Linear regression is a powerful technique for finding a line that approximates a set of data. For the approximation to be a good one, the linear model must be appropriate for the data, which can sometimes be determined by reasoning about the processes that generate the data, and is sometimes justified based on statistical properties of the data. We will use linear models as a tool without elaboration of the methods or theoretical background; you should learn about those in a different statistics course.
We will explore how to create a linear model, which can include a lot more than straight lines, and then discuss how to add those models to a visualization.
17.1 Making linear models
We will always make linear models with variables from a data frame. Designate one variable the response variable, which we will attempt to predict using one or more other variables, called predictors. You are not restricted to variables in your data frame; you can transform the variables first, for example by squaring, taking logarithms, or applying some other function. Additionally, you can use categorical (or factor) variables as predictors and in combination with quantitative variables. Be aware that the more variables or transformations you add to your list of predictors, the more likely they will be correlated and your model will be very hard to interpret. These issues are discussed in statistics courses on regression.
Once your data frame is created, write the linear model as a “formula” object, meaning as an equation but with a ~ instead of an = to indicate that you are modelling the left hand side and allowing for a specific model for the mismatch between predictors and response.
We have seen that the price of a diamond increases a bit faster than linearly as the mass of the diamond increases, we will try both a linear model and a quadratic model for data in the diamonds dataframe.
linear_model1<-lm(price~carat, data =diamonds)summary(linear_model1)
Call:
lm(formula = price ~ carat, data = diamonds)
Residuals:
Min 1Q Median 3Q Max
-18585.3 -804.8 -18.9 537.4 12731.7
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2256.36 13.06 -172.8 <2e-16 ***
carat 7756.43 14.07 551.4 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1549 on 53938 degrees of freedom
Multiple R-squared: 0.8493, Adjusted R-squared: 0.8493
F-statistic: 3.041e+05 on 1 and 53938 DF, p-value: < 2.2e-16
quadratic_model1<-lm(price~poly(carat, 2), data =diamonds)summary(quadratic_model1)
Call:
lm(formula = price ~ poly(carat, 2), data = diamonds)
Residuals:
Min 1Q Median 3Q Max
-26350.0 -724.2 -35.9 445.8 12881.1
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.933e+03 6.631e+00 593.1 <2e-16 ***
poly(carat, 2)1 8.539e+05 1.540e+03 554.4 <2e-16 ***
poly(carat, 2)2 3.757e+04 1.540e+03 24.4 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1540 on 53937 degrees of freedom
Multiple R-squared: 0.851, Adjusted R-squared: 0.851
F-statistic: 1.54e+05 on 2 and 53937 DF, p-value: < 2.2e-16
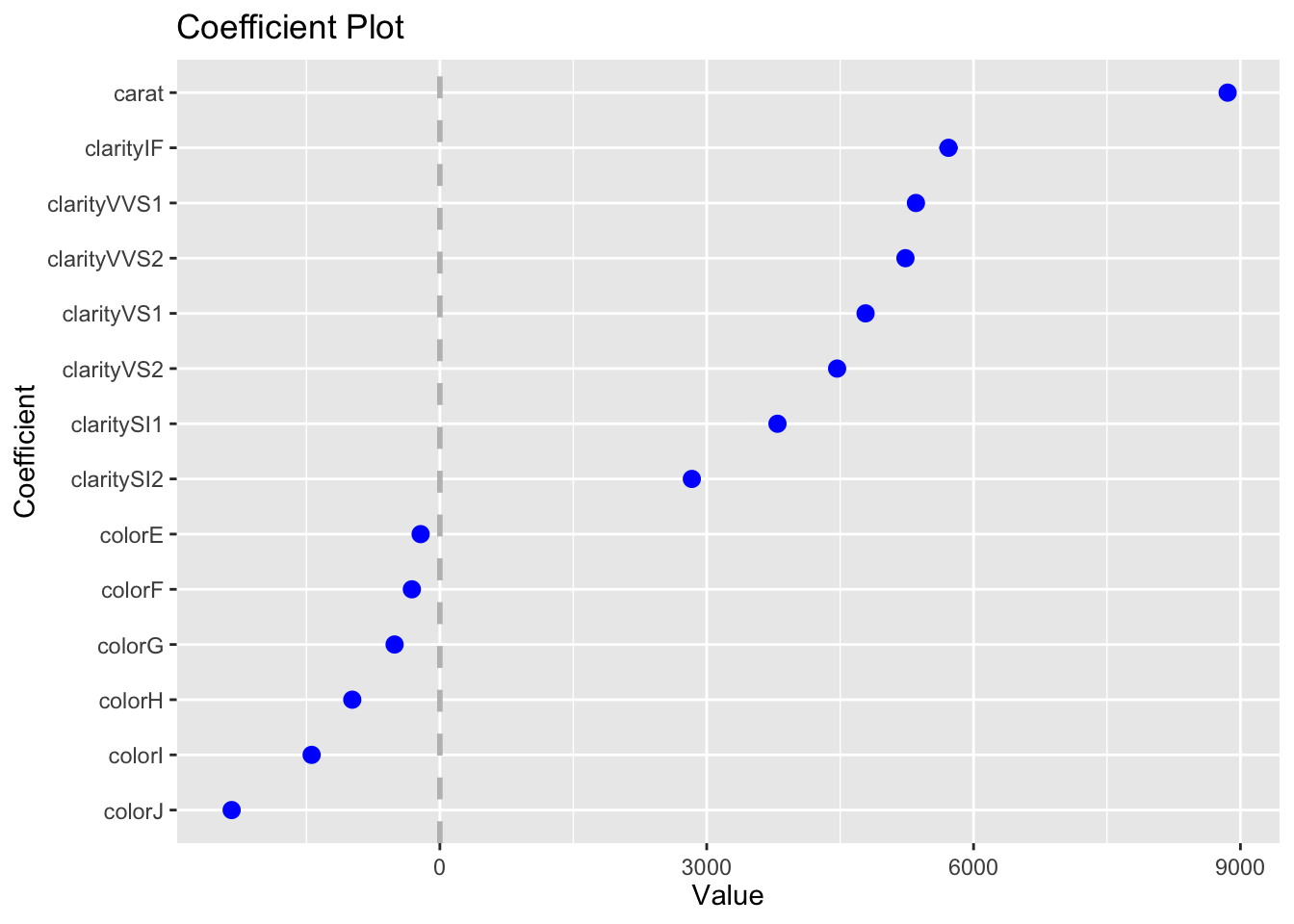
linear_model2<-lm(price~carat+clarity+color, data =diamonds|>mutate(clarity =factor(clarity, ordered=FALSE), color =factor(color, ordered=FALSE)))summary(linear_model2)
You can write the formulas for the regression lines using the equatiomatic package. This package must be installed from GitHub using remotes::install_github("datalorax/equatiomatic"). To get the equations formatted properly, you need to add results='asis' to the {r} line in your R markdown document. The equations display correctly in the knitted document, but are show as LaTeX code in the Rstudio preview. At present this does not work correctly for functions with mathematical transformations like log, exp, poly(x, 2), so I’ll only show the linear models here.
These results are the jumping off point for a lot more exploration.
17.2 Smoothing on facets
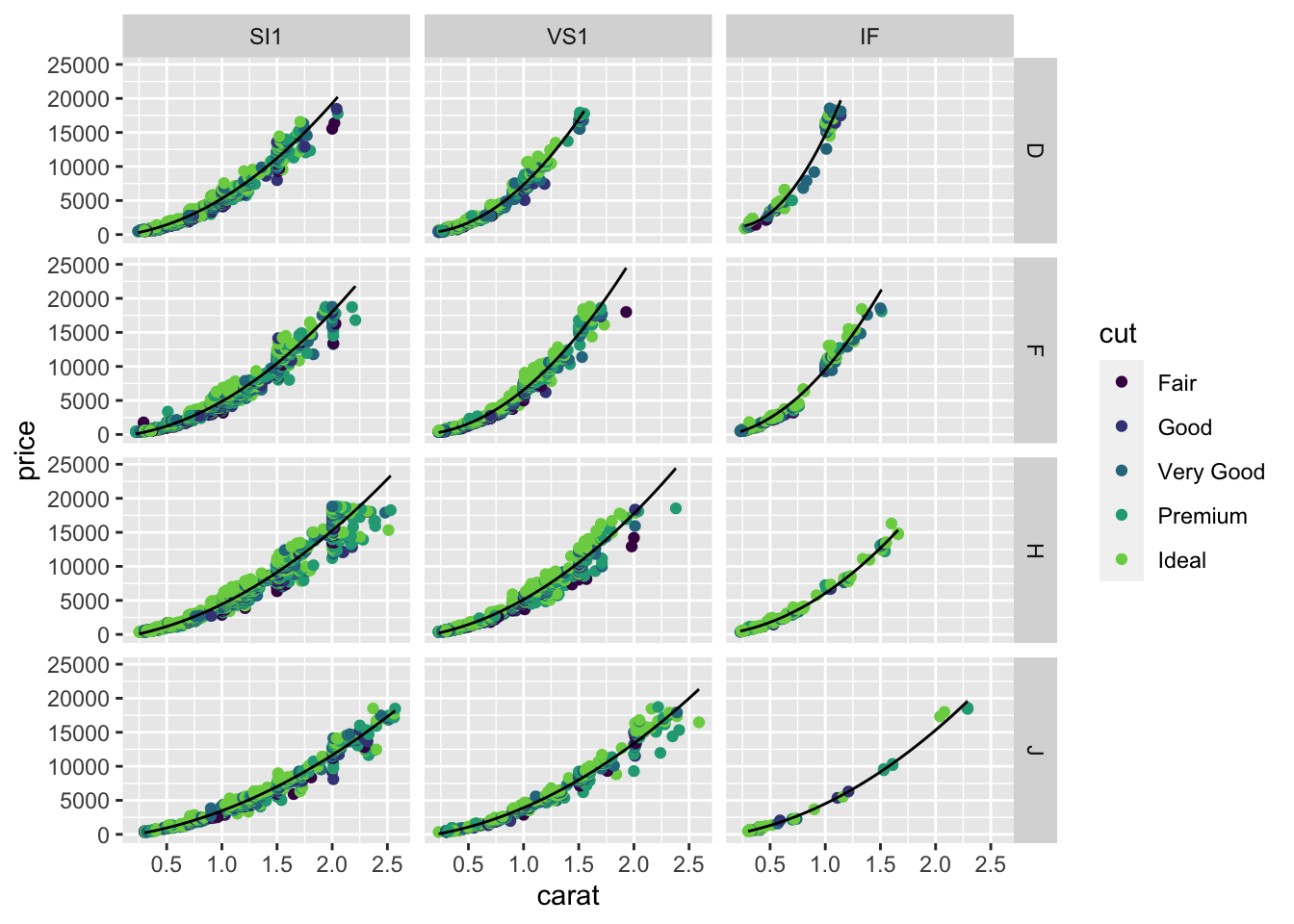
The geom_smooth function is especially powerful for facetted plots. The smooth is automatically computed and plotted for each facet separately.
diamonds|>filter(color%in%c("D", "F", "H", "J"), clarity%in%c("SI1", "VS1", "IF"))|>ggplot(aes(x=carat, y=price))+geom_point(aes(color=cut))+facet_grid(color~clarity)+scale_colour_viridis_d(begin=0, end =0.8)+geom_smooth(method ="lm", formula =y~poly(x,2), color ="black", linewidth =0.5)
You can fit all these lines using lm as well, using color and clarity as variables in the regression equation. The way facet_* and geom_smooth combine together makes the visualization of these lines very easy.
Notice that I’ve moved the color=cut from the ggplot function to the geom_point function as the aesthetic for only the points. If the colour was specified in the first ggplot function, the geom_smooth would “inherit” this aesthetic mapping and would make a separate smooth for each cut (5 lines per panel). There are not enough data in some panels for some cuts to do a good job, so I revised the plot to only draw one smooth per facet. You should move the color=cut back to the ggplot call to see how the result changes.
17.3 Robust regression
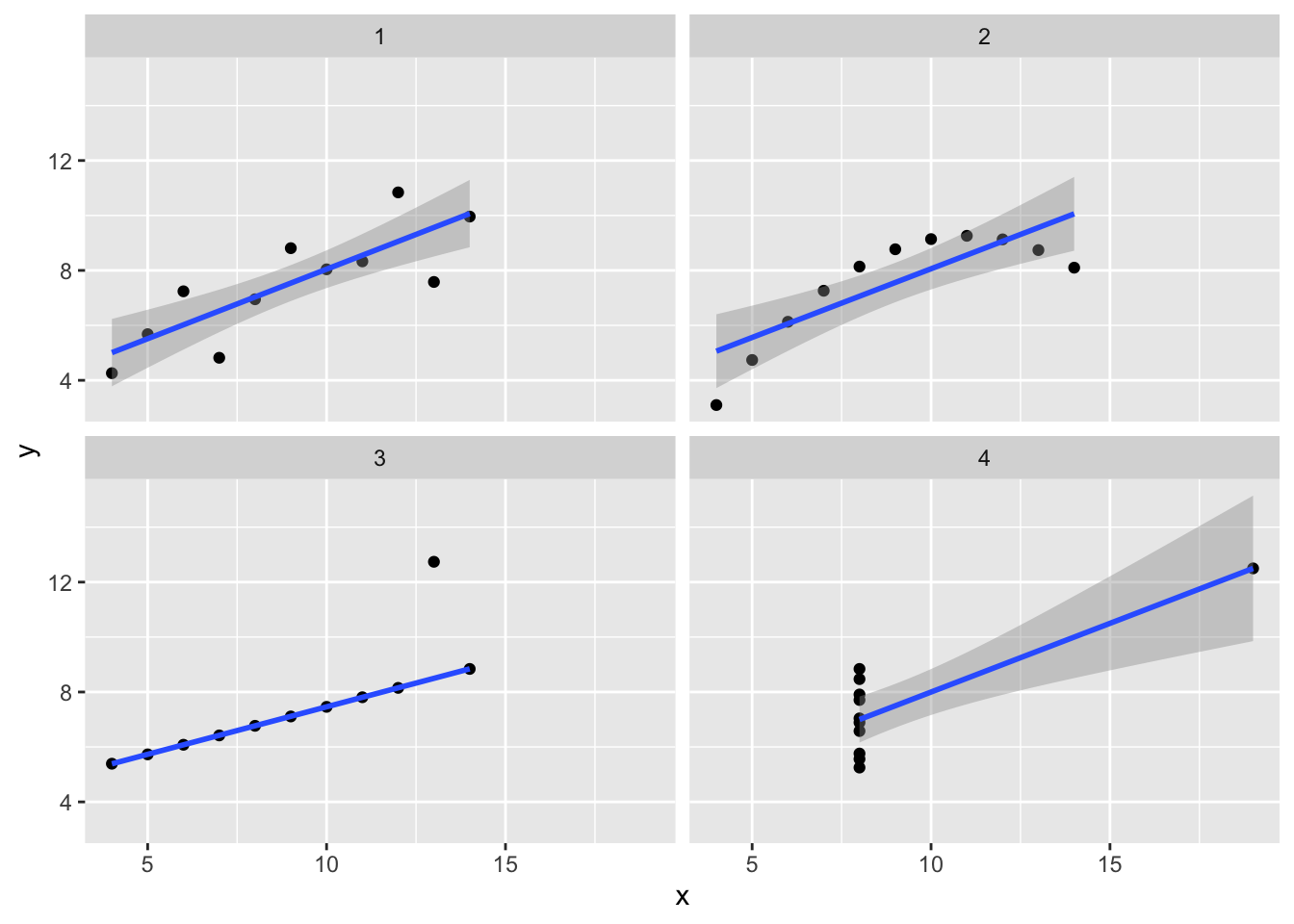
We demonstrated the importance of visualizing data at the start of the course by appealing to the example of Anscombe’s quartet. This is a set of four data sets which all have the same means, standard deviations, and correlation. Here I’ll show how to plot four lines on a single plot and how to avoid at least one of the problems with outliers by using robust regression from the MASS package.
Robust regression is designed to be less influenced by outliers. Robust regression is a big improvement for group 3, but has little effect on any of the other problems. (Try formula = y ~ poly(x,2) to fix panel 2. There is no fix for the problem in panel 4.)
p1<-anscombe|>pivot_longer(everything(), names_to =c(".value", "set"), names_pattern ="(.)(.)")|>ggplot(aes(x =x, y =y))+geom_point()+facet_wrap(~set)# p1 + geom_smooth(method="lm") # Try this insteadp1+geom_smooth(method=MASS::rlm)# , formula = y ~ poly(x,2))
17.4 Predicting quantiles
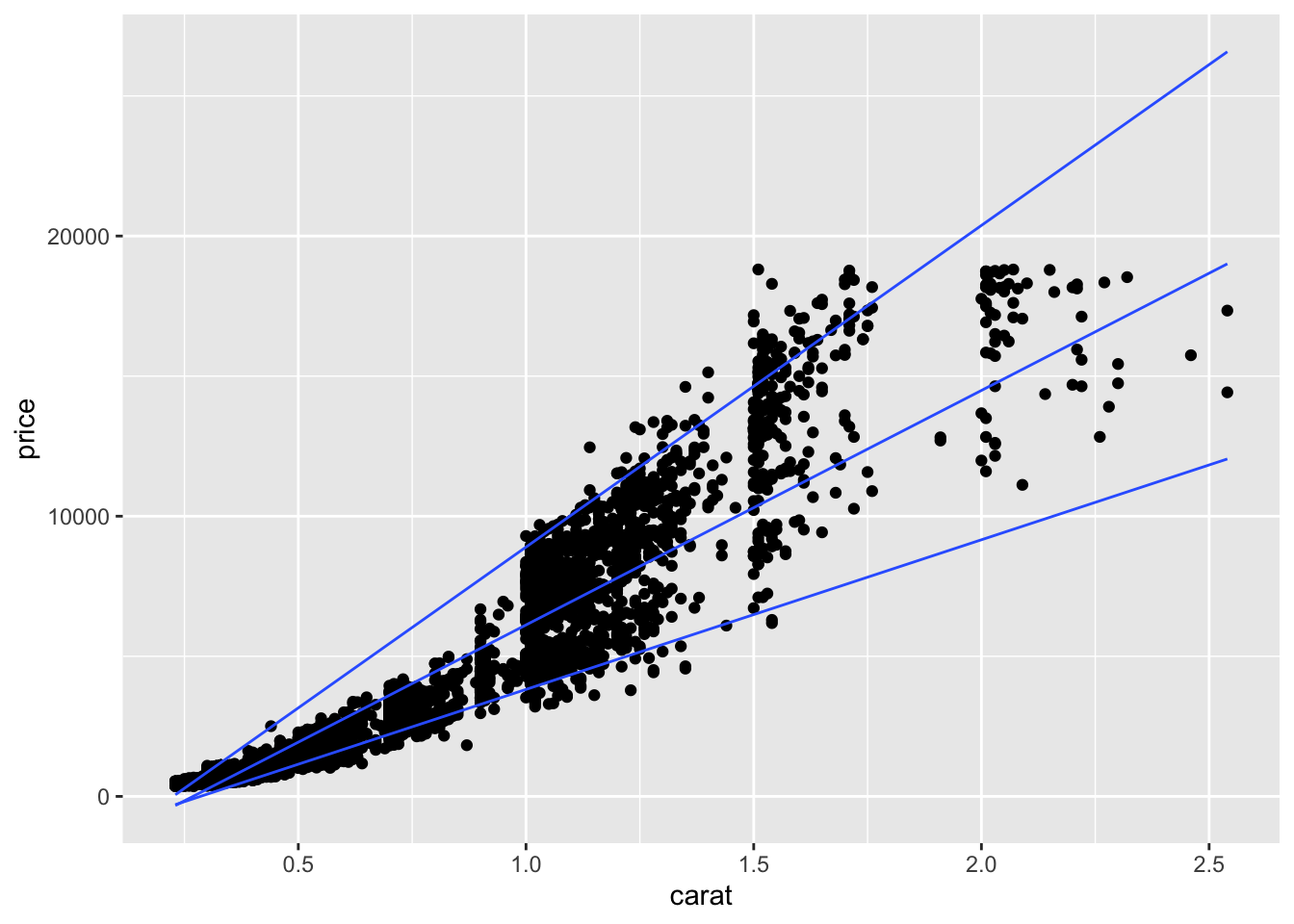
You can also try to predict quantiles of your data. Here we make a linear model for the 0.05, 0.50 (median), and 0.95 quantiles.
diamonds|>filter(cut=="Ideal", color=="G")|>ggplot(aes(x=carat, y =price))+geom_point()+geom_quantile(method =rqss, formula =y~x, lambda =1, quantiles =c(0.05, 0.5, 0.95))
The broom package has functions to obtain model coefficients and compute residuals, predictions, and confindence intervals. Healy also shows how to use broom to fit many models (such as a model for each facet) in his Section 6.6, but I will skip those steps.
Get the coefficients (and standard errors, t-statistic, p-value and confidence intervals) from your model using tidy.
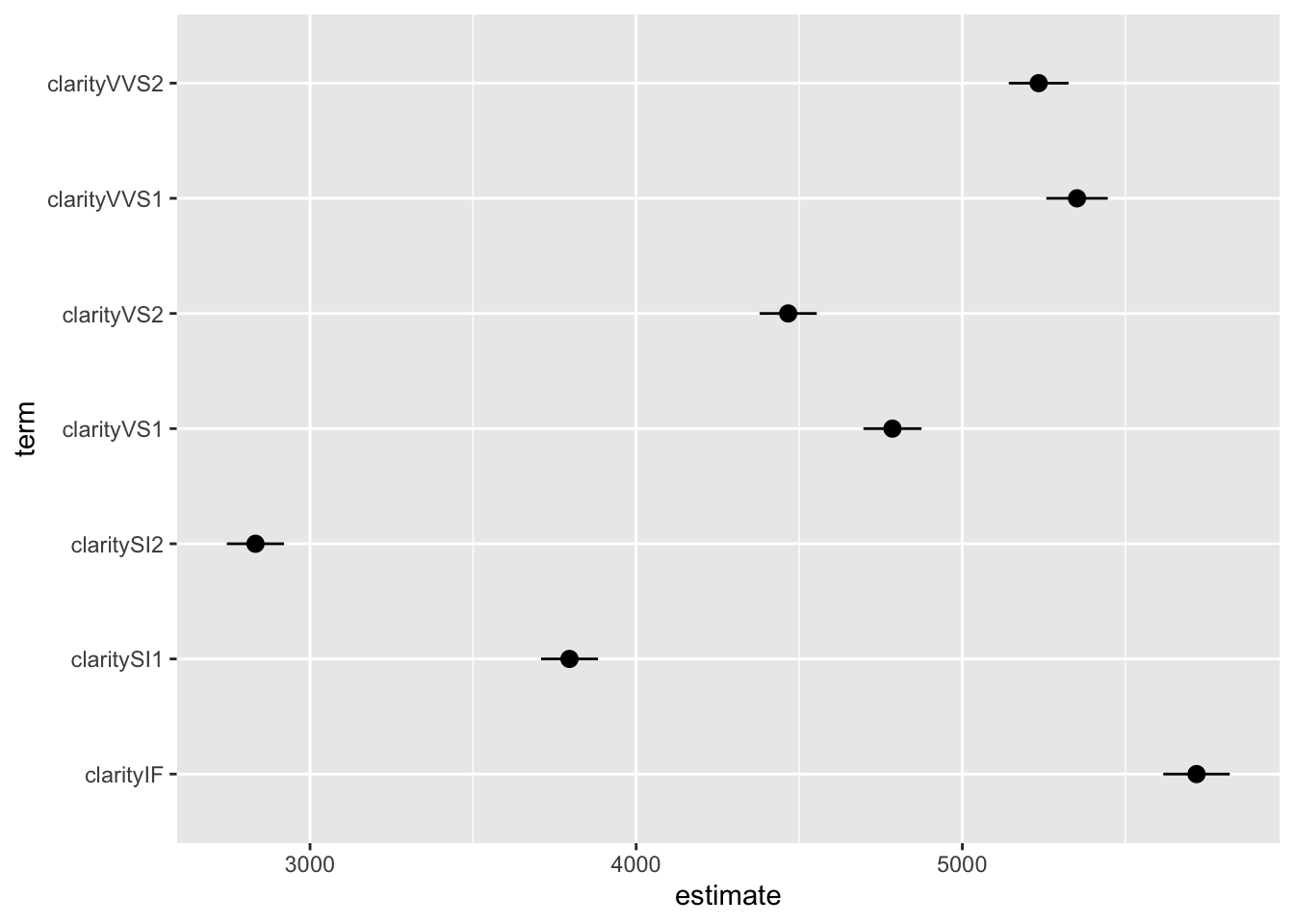
The second model has the effect of each level of clarity on price (relative to the base case of I1). Here’s how we can plot the regression coefficients as dot plots with uncertainties using the output from tidy.
`height` was translated to `width`.
`height` was translated to `width`.
You can get statistics for the model using glance. We don’t discuss these results, but if you have taken a statistics course with topics on regression you should recognize at least some of these results.
glance(linear_model1)|>kable()
r.squared
adj.r.squared
sigma
statistic
p.value
df
logLik
AIC
BIC
deviance
df.residual
nobs
0.8493305
0.8493277
1548.562
304050.9
0
1
-472730.3
945466.5
945493.2
129345695398
53938
53940
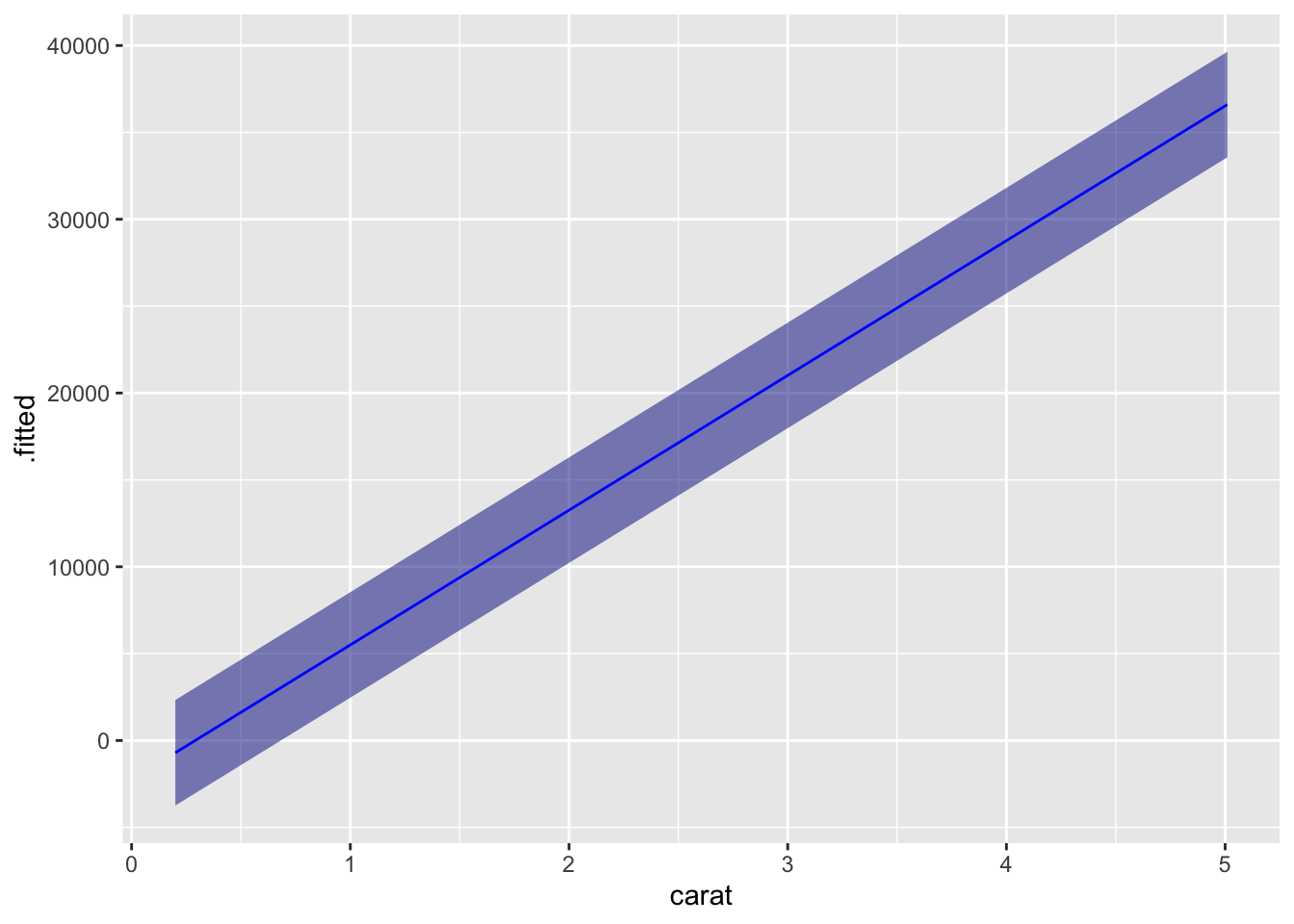
The augment function makes it easy to plot residuals and predicted values for many models (see ?augment). We can use augment on the model object to get a data frame with the data used in the model plus fitted (predicted) values, residuals, and other quantities. You can add the other data not provided in the model object by including data = diamonds in the augment function (output not shown.)
Of course, this is overly complicated for plotting a straight line, but the method can be adopted to many other models.
17.5.1 Revisiting models from the previous lesson
While tidy, glance and augment are very convenient, you will sometimes want simpler methods to get at model results. Here I will show you how to make models and predictions for each of the model types from the previous lesson.
Each of these models can be fitted independently of making a plot. If you do this, you get a complex object called a fitted model that can be used to give you a lot of information about your model. Healy discusses how to look at the model output, but we will skip over this with two exceptions. We will look at the difference between model and data (called residuals) and making predictions with models.
Here we will fit each of the models generated above and look at the summary output from each model. I’ll start by computing log(GDP) and the number of years since 1950 to use as variables in my models.
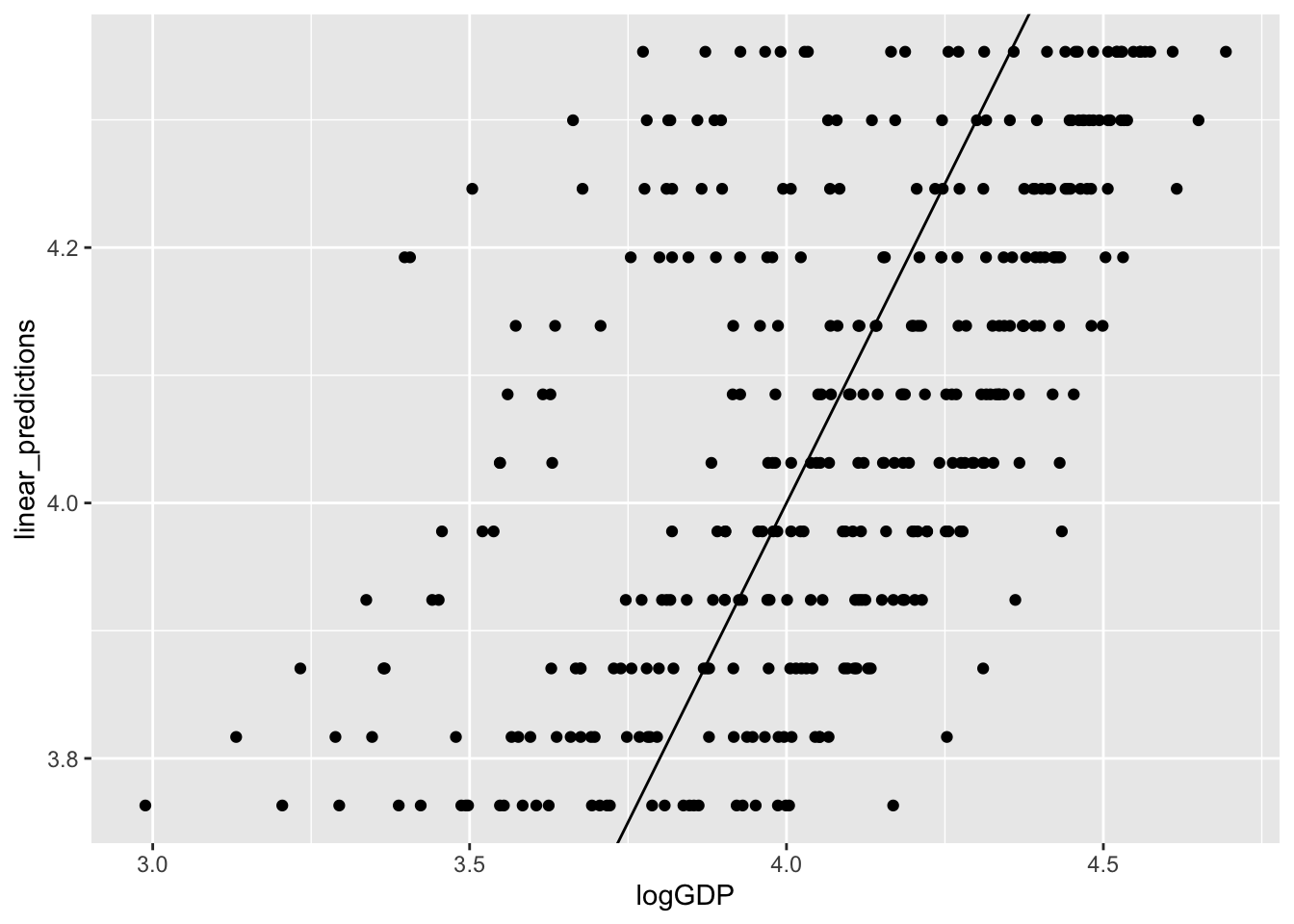
A linear model fitting a straight line to the data (slope, intercept):
gp<-gapminder|>filter(continent=="Europe")|>mutate(year1950 =year-1950, logGDP =log10(gdpPercap))m1<-lm(logGDP~year1950, data =gp)summary(m1)
Call:
lm(formula = logGDP ~ year1950, data = gp)
Residuals:
Min 1Q Median 3Q Max
-0.79487 -0.15384 0.05888 0.20269 0.45675
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.7416631 0.0271072 138.03 <2e-16 ***
year1950 0.0107310 0.0007931 13.53 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2597 on 358 degrees of freedom
Multiple R-squared: 0.3383, Adjusted R-squared: 0.3365
F-statistic: 183.1 on 1 and 358 DF, p-value: < 2.2e-16
A robust version of this line that is less influenced by outliers:
Call: rlm(formula = logGDP ~ year1950, data = gp)
Residuals:
Min 1Q Median 3Q Max
-0.82123 -0.17437 0.03441 0.17481 0.43542
Coefficients:
Value Std. Error t value
(Intercept) 3.7575 0.0264 142.2993
year1950 0.0110 0.0008 14.2157
Residual standard error: 0.2592 on 358 degrees of freedom
Here I fit splines two ways: using lm and using generalized additive models:
m3<-lm(logGDP~splines::bs(year1950, df =5, degree=3), data =gp)m4<-mgcv::gam(logGDP~s(year1950), data =gp)# summary(m3) # this is a bit hard to read, so I don't show it here.# summary(m4) # same comment here!
And finally here is a quantile regression. The quantile predicted by the model is given by tau; we’ve selected the 10 percentile here. lambda is a parameter that
m6<-quantreg::rq(logGDP~year1950, data=gp,# slice_sample(gp, n = 349, replace=TRUE), # no warning message tau =0.10)summary(m6)
Warning in rq.fit.br(x, y, tau = tau, ci = TRUE, ...): Solution may be
nonunique
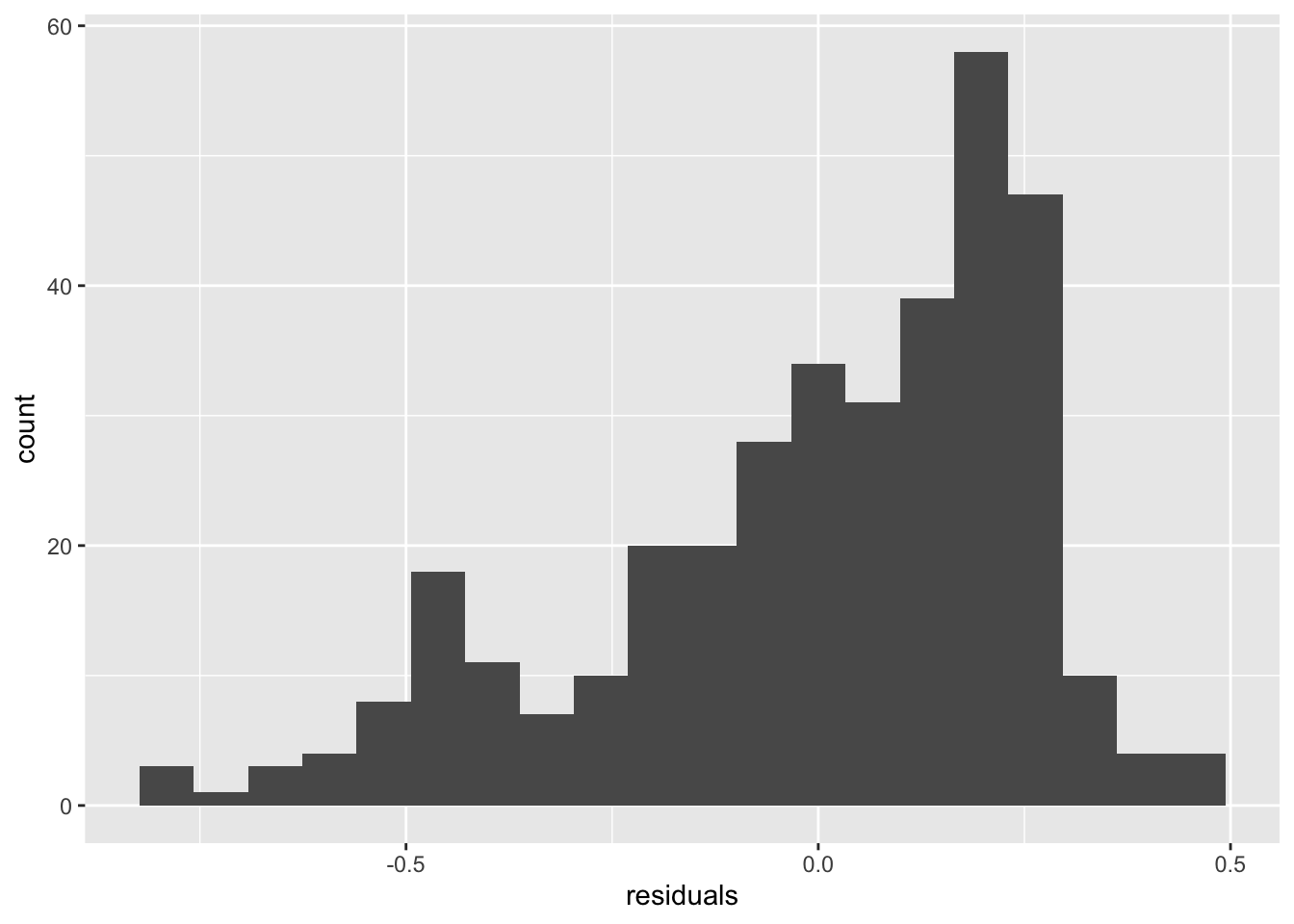
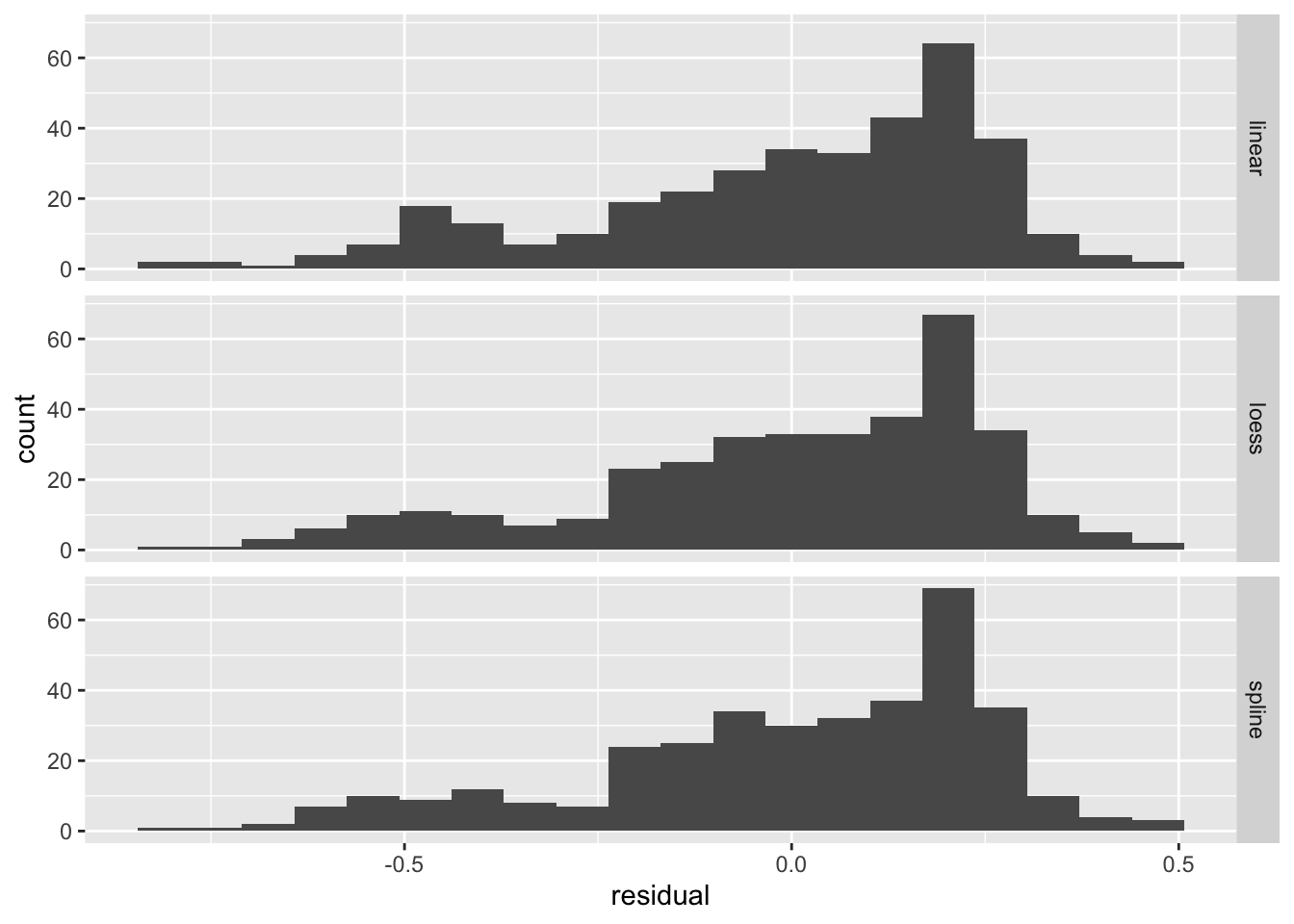
An important visualization for any model is to compare observations with the predictions of the model. This difference is called the residual. (From the residual variation in the data not described by the model.) The function residuals applied to the model object gives you access to these values and makes them easy to plot.
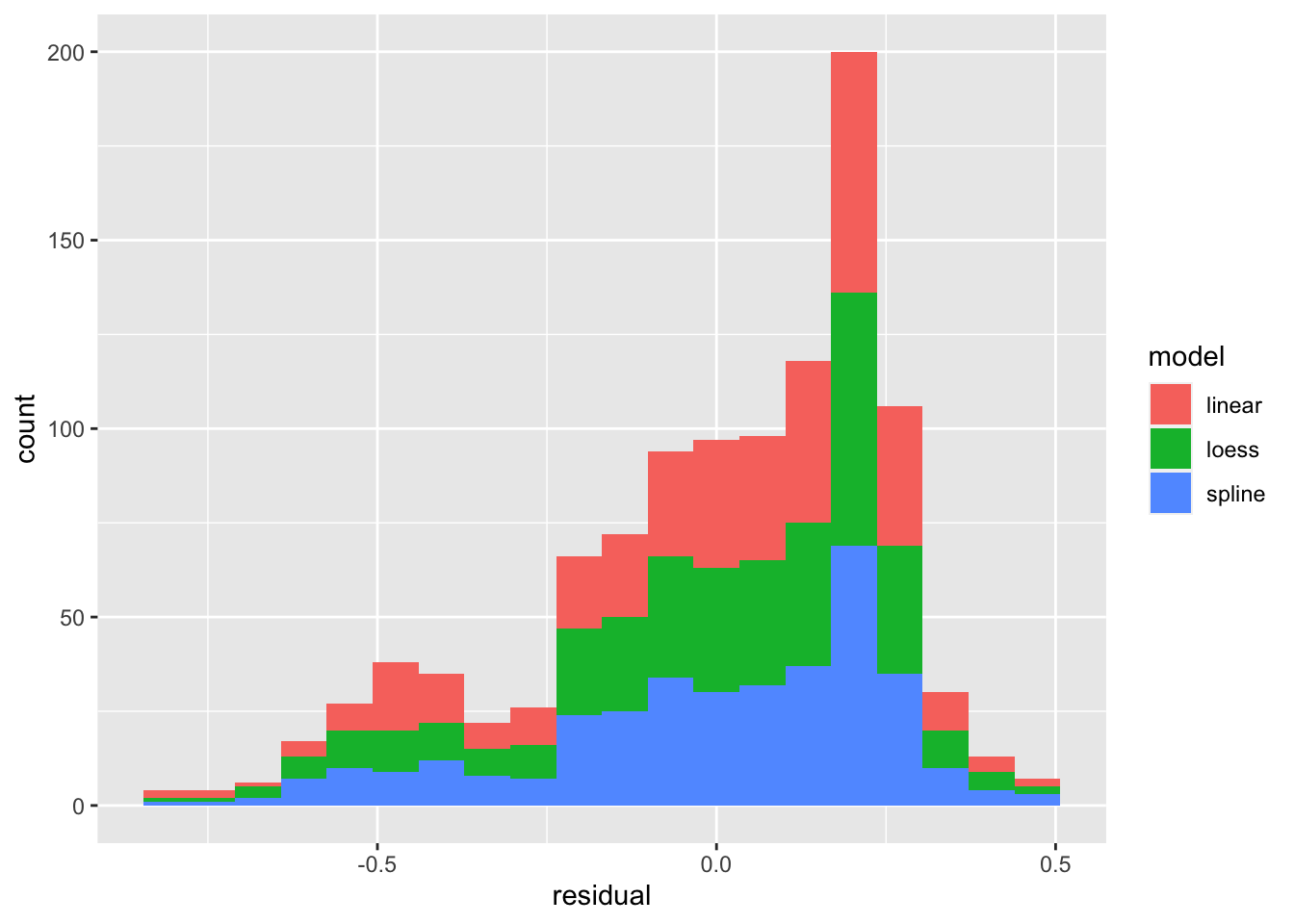
We can see that the distribution (histogram) of the residuals is fairly similar for all three models. There are defintely negative residuals larger in magnitude than any of the positive residuals. The modal residuals are bigger than zero. This suggests there are some points where the model “over predicts” (model prediction larger than observed data) and the most common result is an under prediction (model prediction is smaller than observed value.)
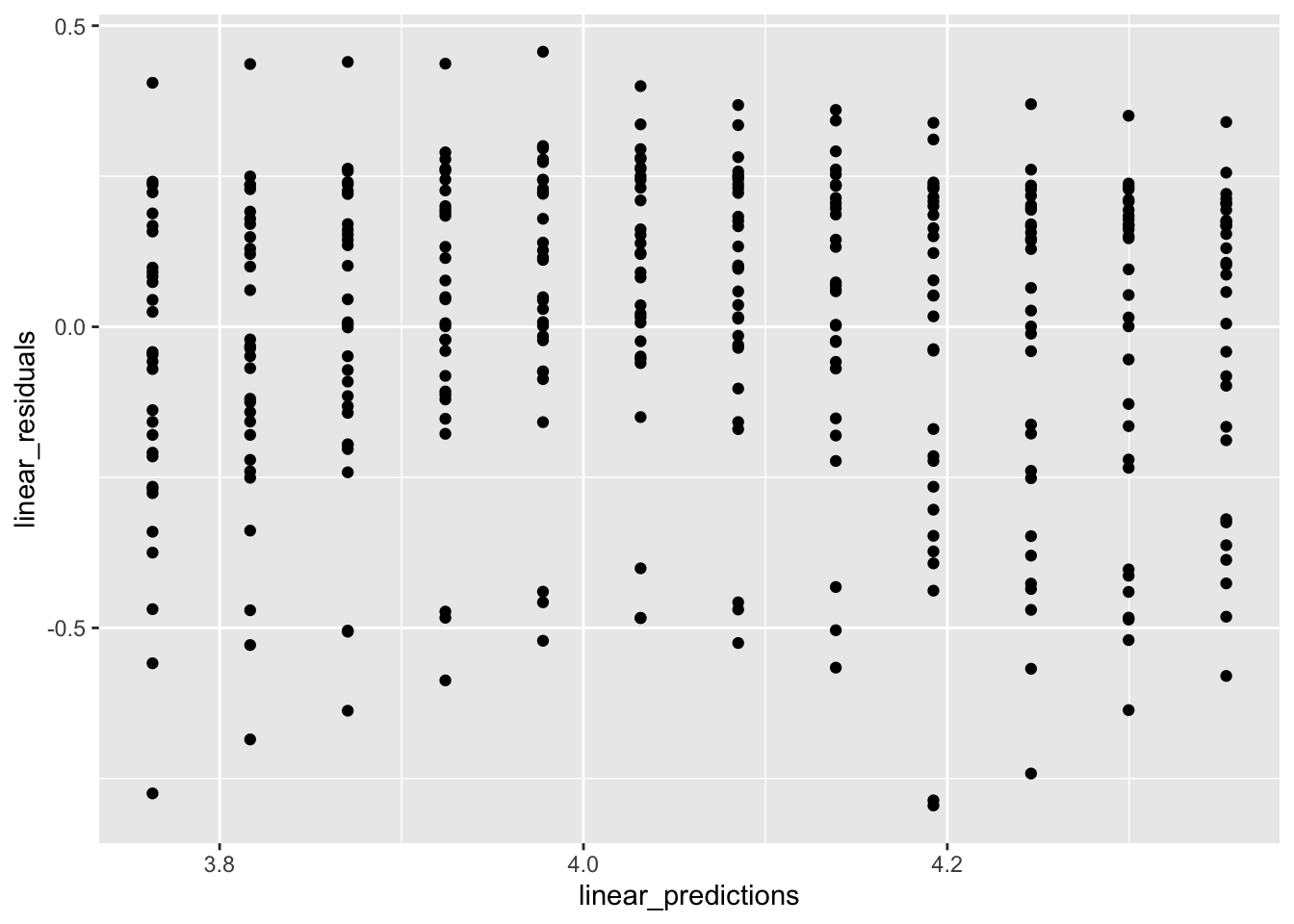
More commonly you will want to compare the residuals to one of the independent variable, dependent variable, or predicted values. This is easy to do by adding predictions and residuals to the original data.
Note that models generally don’t make predictions from missing data, so if year or GDP data were missing, for any country or year, there would be some problems with the code above. The easiest solution is to filter out all rows from your data table that have missing data.
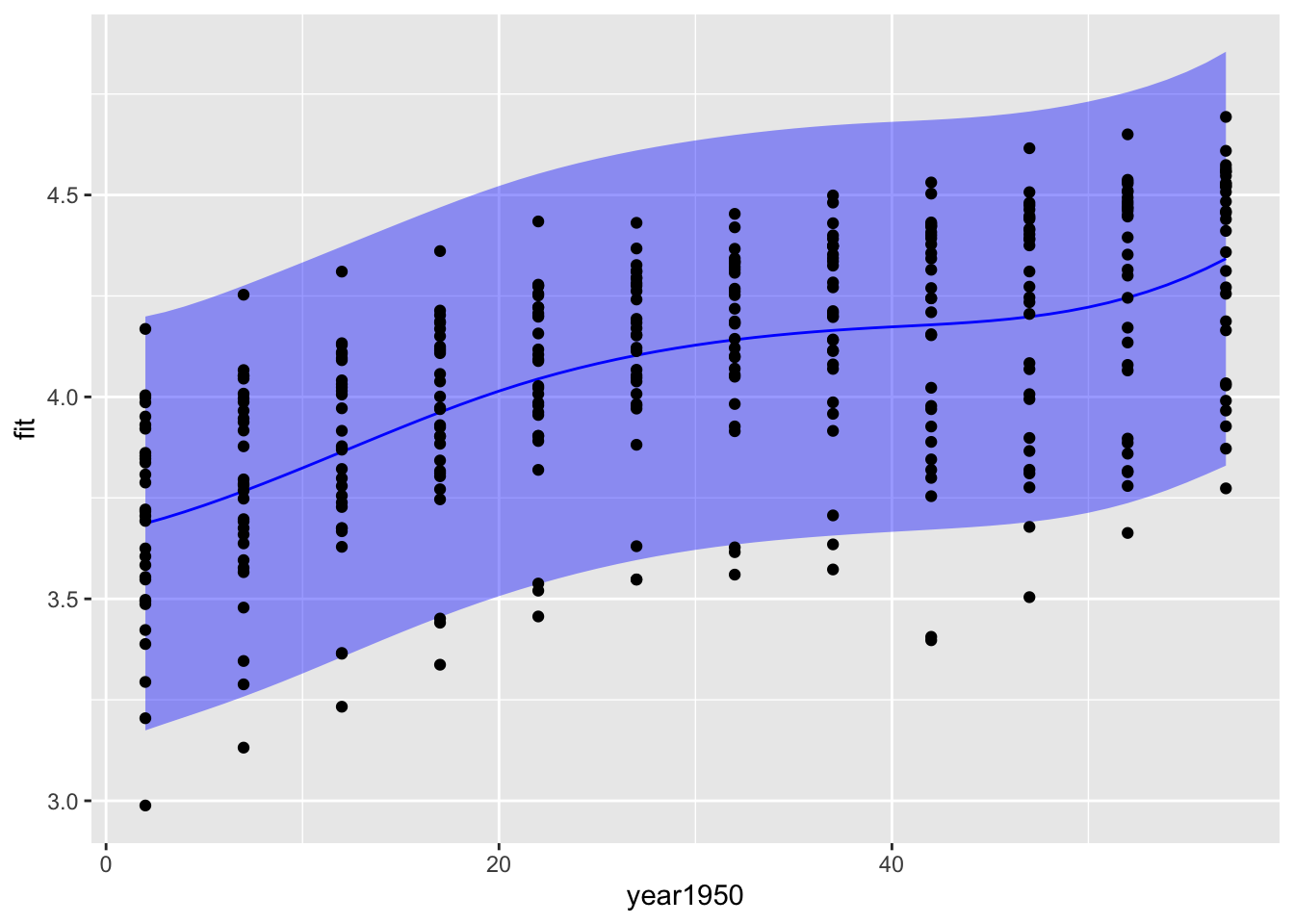
When making predictions, you can also generate confidence or prediction intervals to add a measure of uncertainty to your visualization. For plotting purposes you may want to generate a uniform grid along the x-axis and make predictions for these values. Here’s how you can do that. I’ve used summarize to determine the range of the years since 1950 (not shown). You should always be very cautious interpreting predictions, but especially predictions for values outside the observed values in your original data.
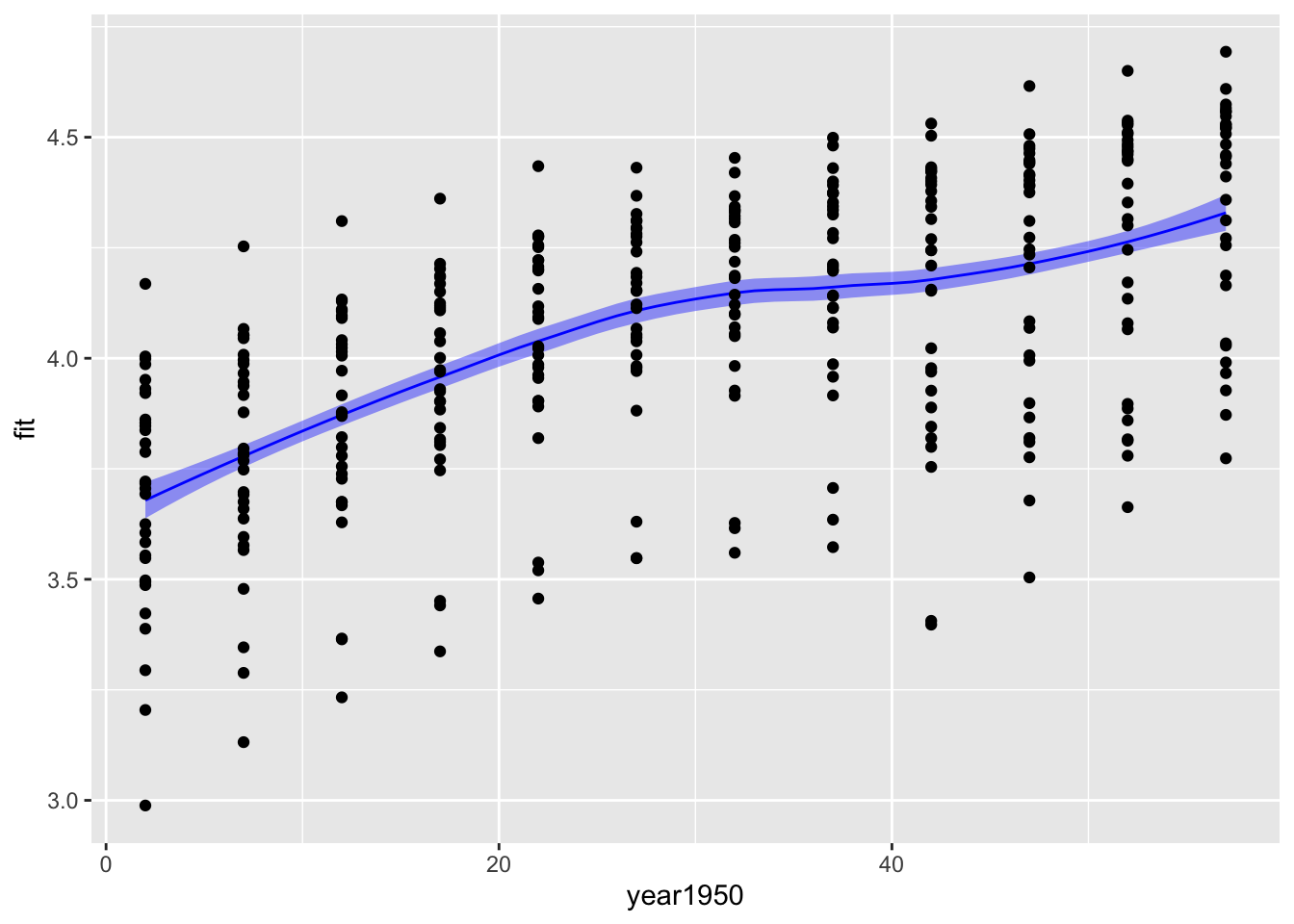
new_data<-tibble(year1950 =seq(from =2, to =57, by =1))predictions1<-predict(m3, new_data, interval ="prediction")|>as_tibble()predictions2<-predict(m5, new_data, se=TRUE)|>as_tibble()bind_cols(new_data, predictions1)|>ggplot(aes(x =year1950, y =fit))+geom_ribbon(aes(ymin =lwr, ymax =upr), fill ="blue", alpha =0.4)+geom_line(color ="blue")+geom_point(data =gp, aes(x =year1950, y =logGDP))
bind_cols(new_data, predictions2)|>ggplot(aes(x =year1950, y =fit))+geom_ribbon(aes(ymin =fit-se.fit, ymax =fit+se.fit), fill ="blue", alpha =0.4)+geom_line(color ="blue")+geom_point(data =gp, aes(x =year1950, y =logGDP))
The confidence intervals are a lot narrower than the prediction intervals. The confidence interval gives you a measure of the uncertainty in the mean value of log GDP per capita for each year, while the prediction interval gives you a measure of uncertainty in a prediction for a new observation of log GDP per capita. The prediction of a new observation should be much more uncertain than your knowledge of the mean from all the data.
A few technical observations. predict does not generate a data frame; it makes a matrix, so we use as_tibble to convert it to a tibble so that variable names work as expected. The predict functions for linear models, GAMs, LOESS, etc are all different functions and have some important differences. Here you can see that the spline can calculate prediction or confidence intervals and the output is the upper and lower limits of the interval. The LOESS predict function only calculates the standard error of the estimated value; this value must be scaled and added to the predicted value to generate an uncertainty estimate.
17.6 Packages used
In addition to the tidyverse, this lesson used
gapminder for its data
quantreg for quantile regression
kableExtra for formatting tables
broom for looking at output of models (glance, augment)
MASS for rlm
mgcv for gam
equatiomatic for formatting regression equations from models
coefplot
splines for regression with splines
Notes:
geom_quantile may generate a warning message containing the phrase “non-list contrasts argument ignored”. This message arises from a technical problem arising when one package is updated independently of another. You can safely ignore this warning message.
Quantile regression (function rq) may give a warning message containing the phrase “Solution may be nonunique”. This arises from the difficulty of computing quantiles with an even number of data points or discrete data. It is usually safe to ignore this error. You can try a new analysis with a random sample of the data to see if the result changes if you want to be sure.