── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.2.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors8 Using the grammar of graphics
8.1 Goals
In this lesson I will demonstrate how to use R and ggplot2 to make visualizations using the ideas from the previous lesson. The emphasis is on the mechanics of making the visualizations. In time we will integrate the ideas about what features of visualizations work best to convey an idea that were introduced at the start of the course.
8.2 Introduction
By the end of this lesson you should understand how to make many different plots using ggplot. The mental model developed in the previous lesson will connect directly to the R commands in this lesson.
Hadley Wickham, who originally developed ggplot2 is from New Zealand. One consequence is that he allows for “British” and “American” spellings of some words. So you can use color or colour to make an aesthetic mapping between data and colour on a plot. In a future lesson when we summarize data you’ll see we can write summarize or summarise. If I switch back and forth, don’t get confused. Both are OK.
8.3 Data
We will use the diamonds dataset for examples in this lesson. As always, you should use str or View to take a look at the data to familiarize yourself with the variables and the number of rows in the data before you begin to make a plot.
str(diamonds)tibble [53,940 × 10] (S3: tbl_df/tbl/data.frame)
$ carat : num [1:53940] 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ...
$ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ...
$ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ...
$ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ...
$ depth : num [1:53940] 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ...
$ table : num [1:53940] 55 61 65 58 58 57 57 55 61 61 ...
$ price : int [1:53940] 326 326 327 334 335 336 336 337 337 338 ...
$ x : num [1:53940] 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ...
$ y : num [1:53940] 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ...
$ z : num [1:53940] 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...This is a large dataset, with over 50,000 rows. There are 7 quantitative variables and three categorical variables. Read the help page on the dataset to learn more.
8.4 Aesthetic mappings and geometries
We usually pick the aesthetic mappings once we’ve thought about what geometry we want to use. In this lesson we will demonstrate the following plots: histogram, boxplot, and scatterplot. For a survey of other common geometries, consult Wilke, chapter 5. Even these three geometries give us lots of room to show of the power of the grammar of graphics.
8.5 Histogram
Let’s draw a histogram of the price of diamonds in the dataset. We map price to the x axis and request the histogram geometry. This geometry will compute the bins along the axis and count the number of observations per bin for us without further instruction.
diamonds |>
ggplot(aes(x=price)) +
geom_histogram()`stat_bin()` using `bins = 30`. Pick better value `binwidth`.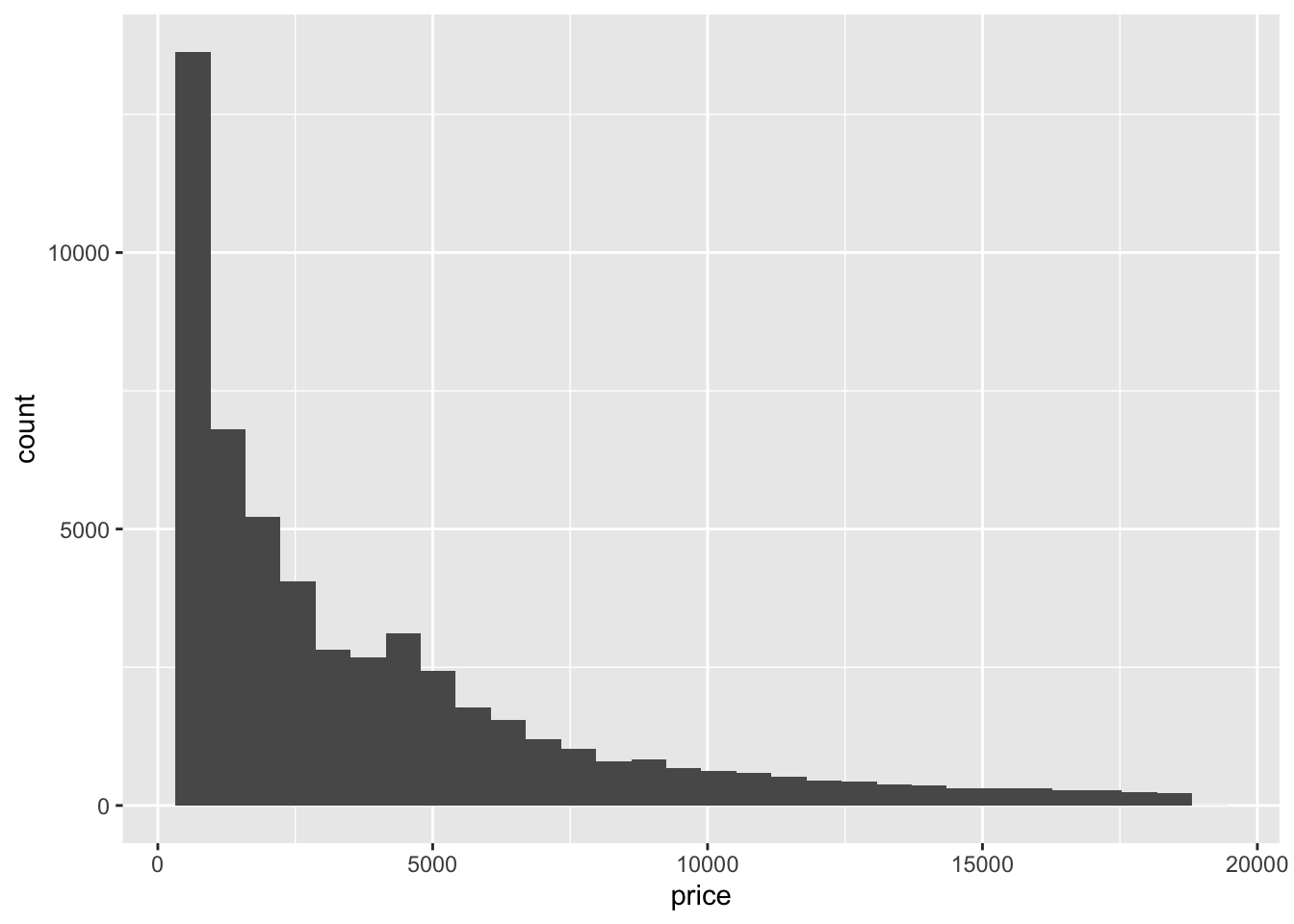
If you don’t specify the number of bins to use or the width of each bin, R will display a warning message. Ignore the warning for now.
This is very skewed distribution, Most observations are at the low end of the price range.
Maybe one of the categorical variables will help us see features in the data. Let’s break the bars down by cut using colour. We will use the fill aesthetic to fill the bars with a colour according to this variable.
diamonds |>
ggplot(aes(x=price, fill=cut)) +
geom_histogram()`stat_bin()` using `bins = 30`. Pick better value `binwidth`.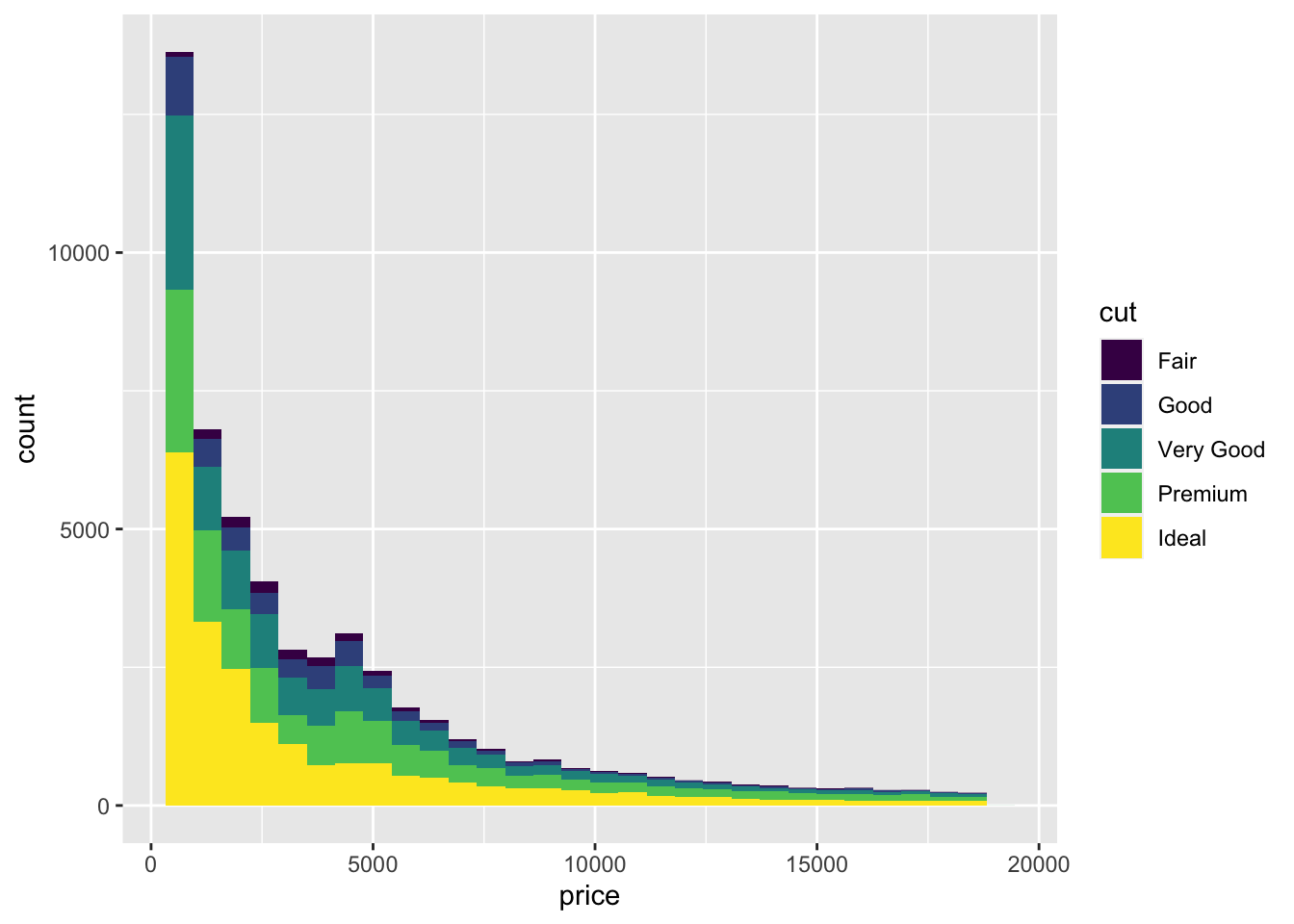
For skewed distribution of positive numbers, a log transform can sometimes help reveal patterns. Let’s change the scale to see if that works.
diamonds |>
ggplot(aes(x=price, fill=cut)) +
geom_histogram() +
scale_x_log10()`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
Stacked bar graphs like this are interesting, but they can be hard to read because it’s hard to make quantitative comparisons across bars at the top of each stack. Is the distribution the same for all the cuts? Or are there more Premium and Very Good cuts for the more expensive diamonds? Let’s try a few different ways to split the histogram.
We can modify the geometry by modifing the histogram geom. It’s helpful to have fewer bars in this histogram, so I’ve set the number of bars to 10 using bins=10. I’ve also rearranged the bars to be side-by-side instead of stacked using the notation position="dodge".
diamonds |>
ggplot(aes(x=price, fill=cut)) +
scale_x_log10() +
geom_histogram(bins = 10, position="dodge")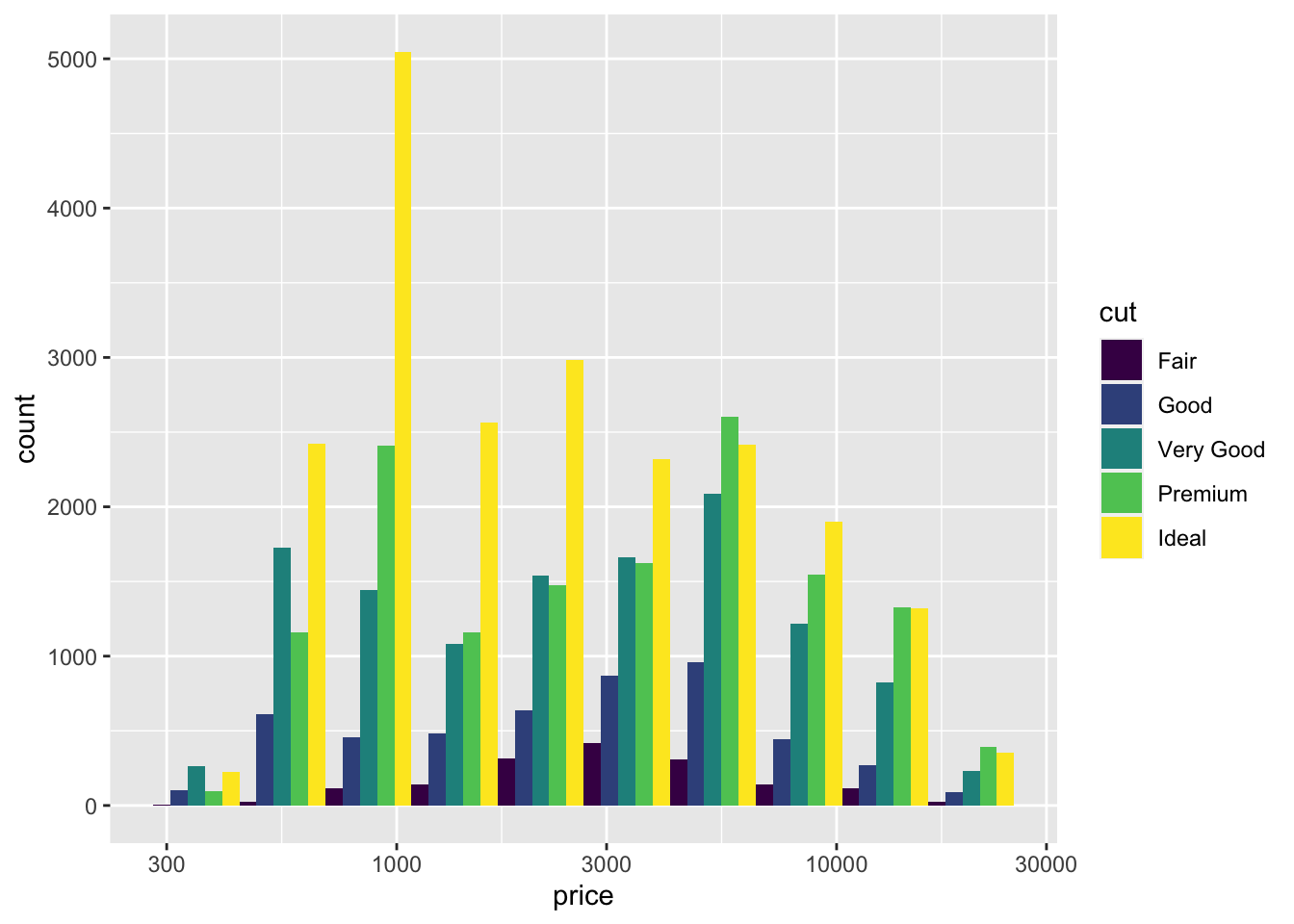
The peak for Ideal cuts seems to be at a lower price than the peak for Premium or Very Good cuts.
8.6 Box plots
Box plots are useful for showing distributions too. You can draw a box plot with one quantitative variable, or with a quantitative variable and a categorical variable. You can use either x or y for the quantitative variable. A plot with too many colours is hard to read, but we can interpret lots of side-by-side boxplots. For variety, I’ll switch to clarity for the categorical variable. You should make these plots with cut as the categorical variable to compare with the histograms above.
diamonds |>
ggplot(aes(x = price, y = clarity)) + geom_boxplot()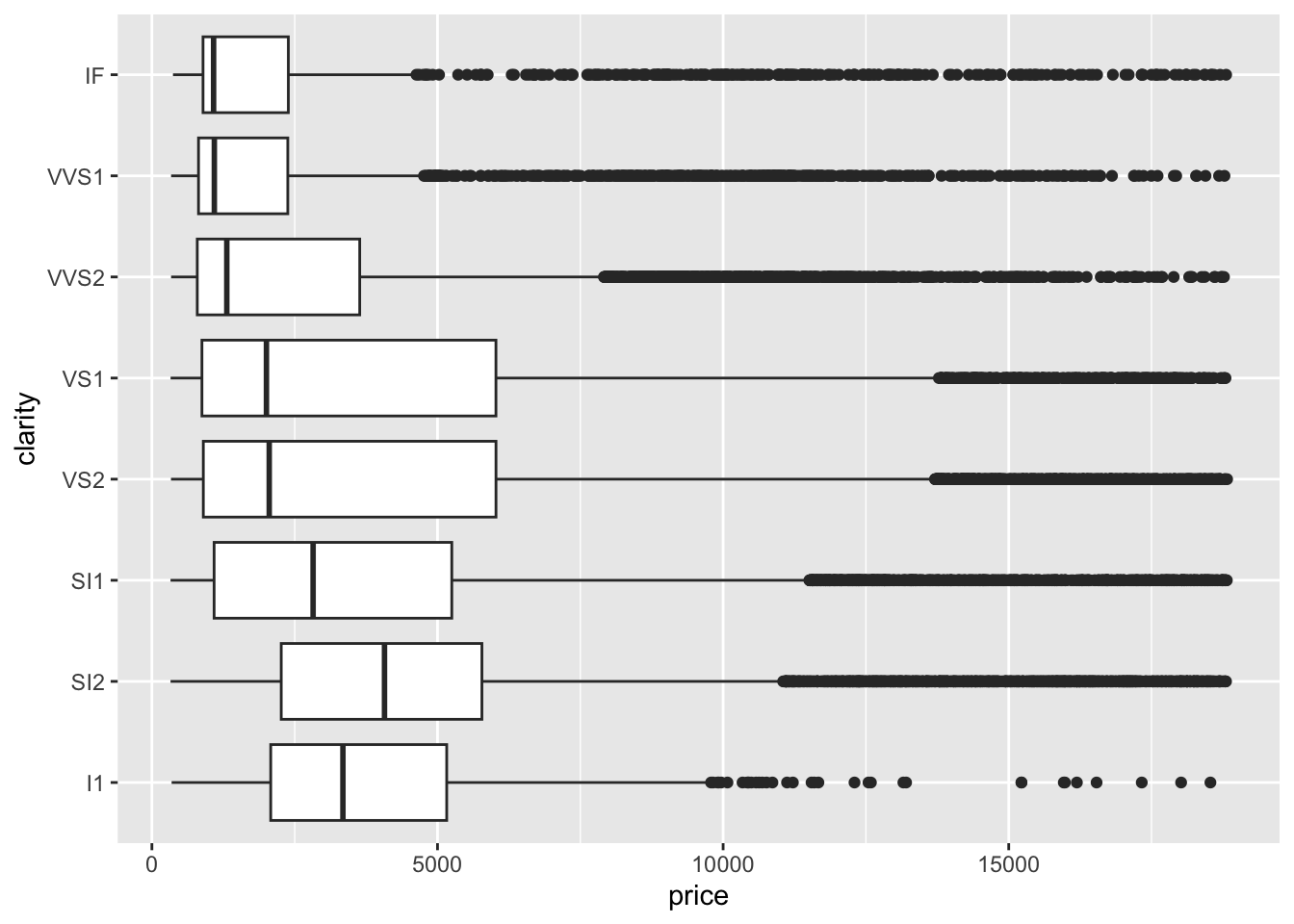
As before the distributions are skewed, so let’s use the log transform again. Notice how similar the code is to the code we used to make a histogram.
diamonds |>
ggplot(aes(x = price, y = clarity)) +
geom_boxplot() + scale_x_log10()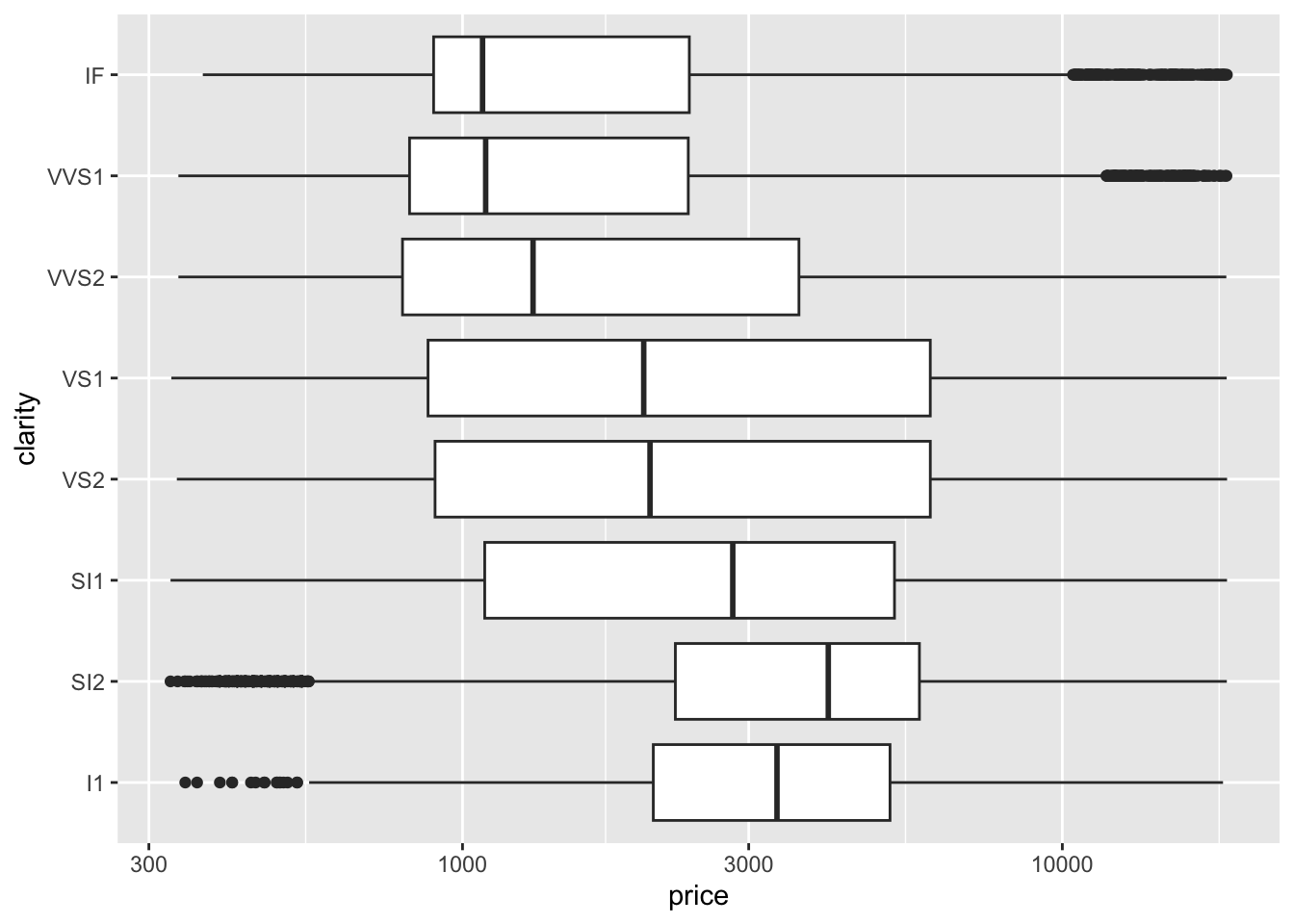
If you are willing to read a complex plot, you can fill the boxes using cut. (Try color= instead of fill= to compare the two ways of using colour.) This figure is probably too complicated to show someone else, but might be useful as an exploratory plot to see a lot of information in a small space. Think carefully about what is being shown here – a summary of over 50,000 prices across two categorical variables with 5 x 8 = 40 different combinations!
diamonds |>
ggplot(aes(x = price, y = clarity, fill = cut)) +
geom_boxplot() + scale_x_log10()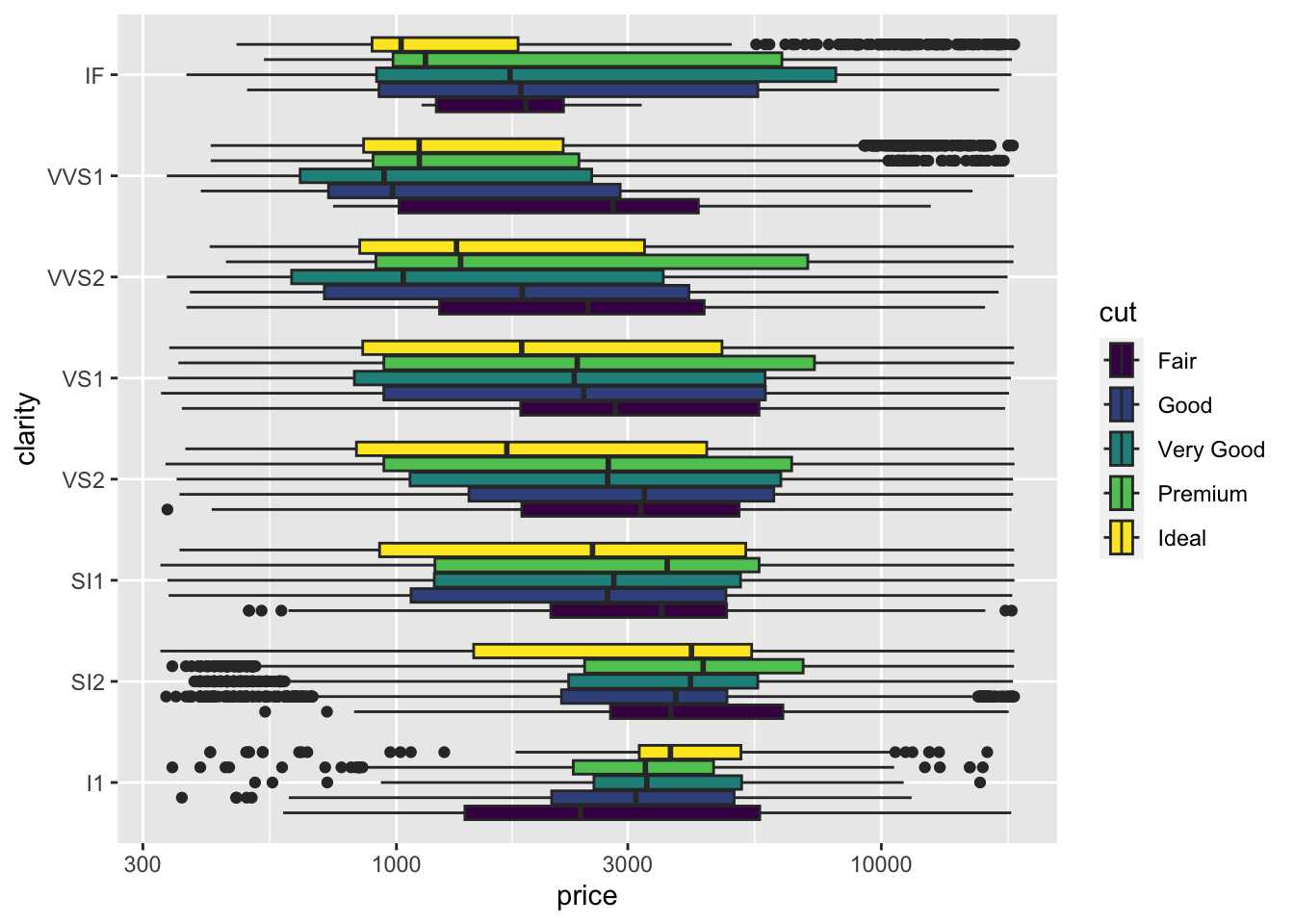
To my eye it looks like price increases gradually with improvements in cut or clarity – but if you think about it carefully the patterns might be confusing. Presumably the size (carat) of each diamond is important too!
8.7 Scatter plot
For our third geom, we will use geom_point to make a scatter plot. Just knowing the name of the geometry tells you all you need to know to create the plot below by modifying the code above. In the code below, I changed geom_boxplot to geom_point, changed fill to color and changed clarity to carat to have a second quantative variable on the y axis.
diamonds |>
ggplot(aes(x = price, y = carat, color= cut)) +
geom_point() + scale_x_log10()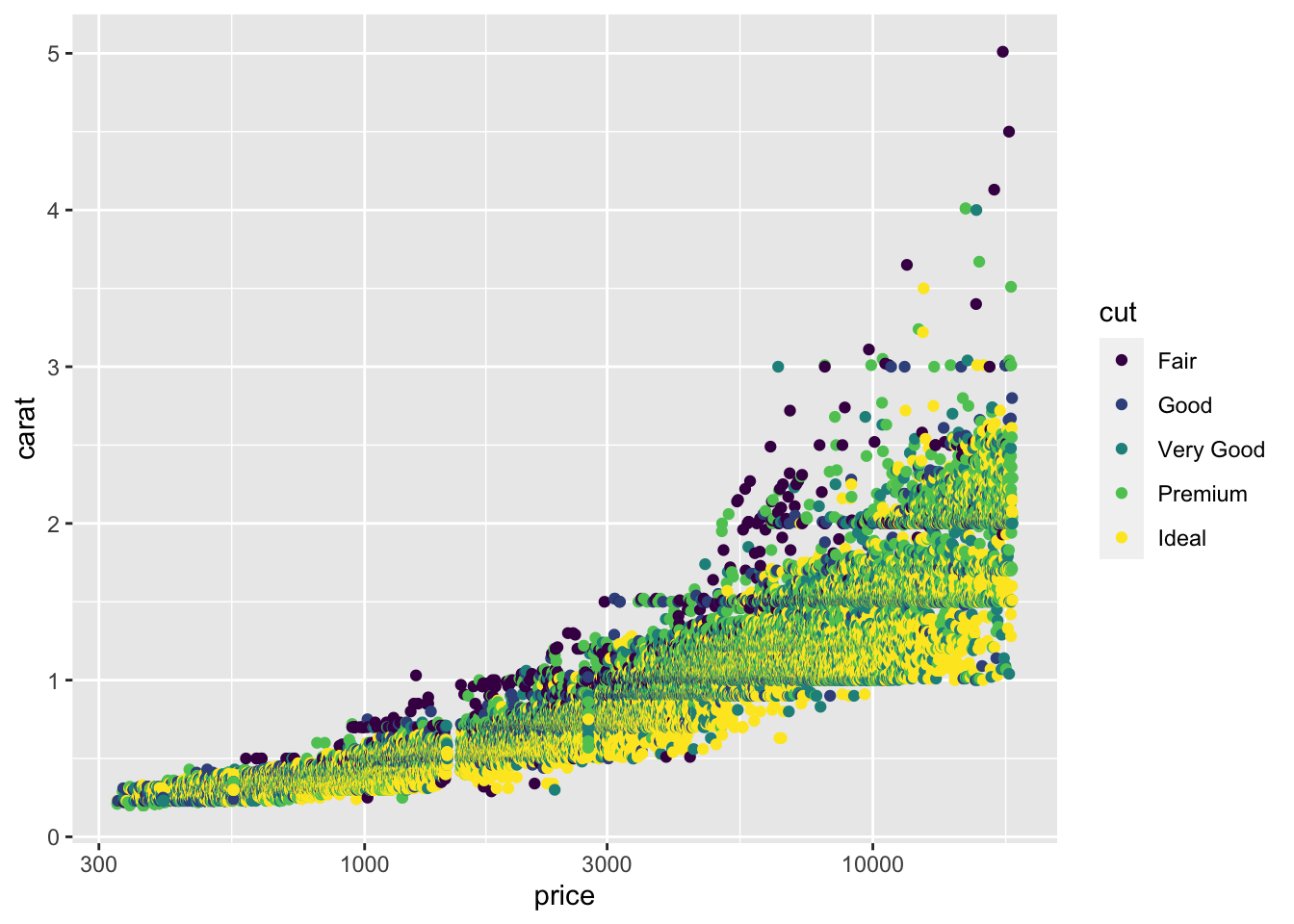
That’s too many points on a scatter plot! There are a few tricks you can use, like making the points smaller (size) and making them partly transparent (alpha) but they don’t really help with this much data.
diamonds |>
ggplot(aes(x = price, y = carat, color= cut)) +
geom_point(alpha = 0.5, size = 0.2) +
scale_x_log10() 
8.8 Two dimensional histogram
How can we visualize how many points are overlapping in that cloud of data? Let’s create a histogram with two quantitative variables and show the height of each bar using color.
diamonds |>
ggplot(aes(x = price, y = carat)) +
geom_bin2d() + scale_x_log10()`stat_bin2d()` using `bins = 30`. Pick better value `binwidth`.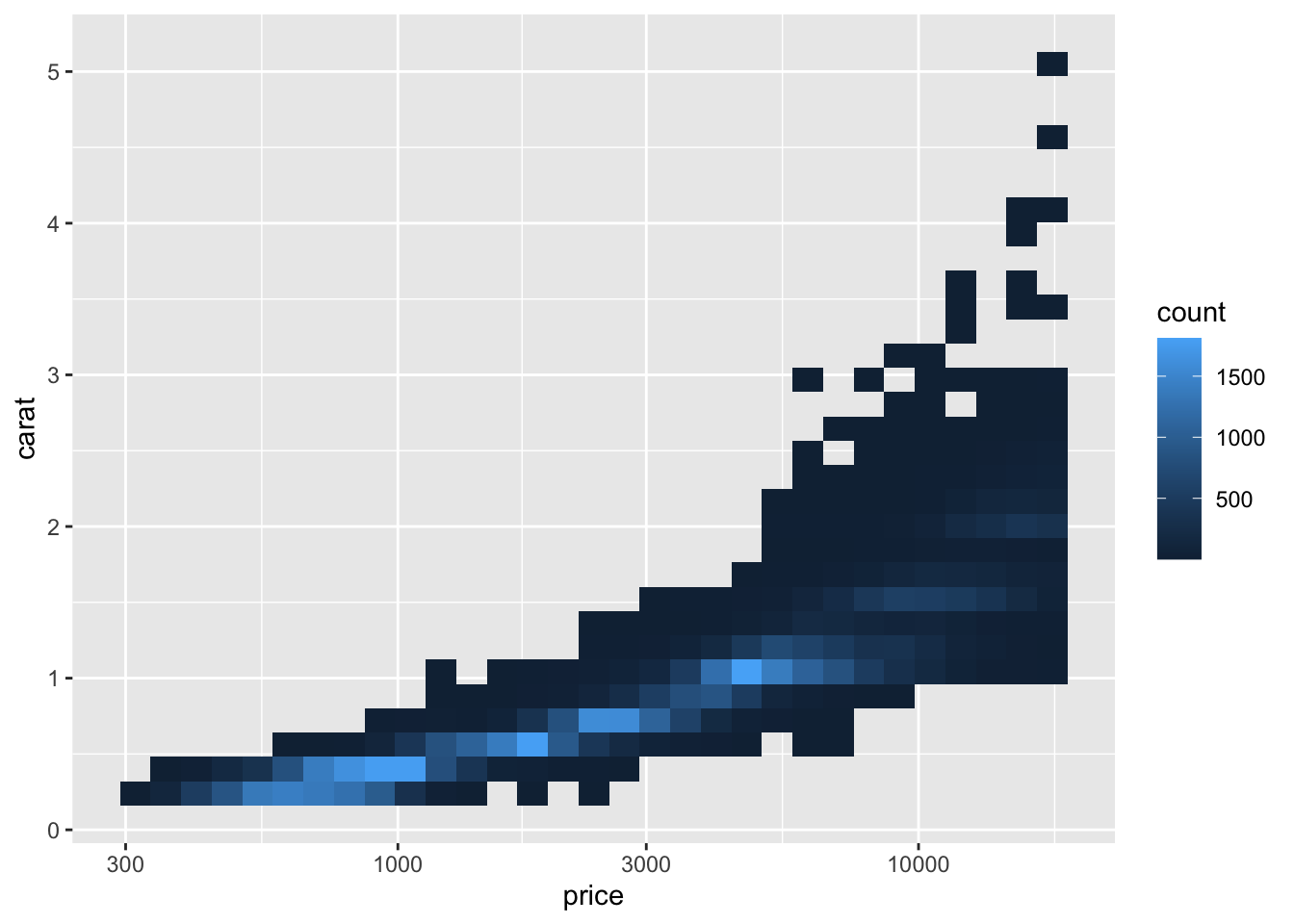
Accurate quantitative assessment is hard to make (basically impossible) with colour brightness, but you can see the price and carat combinations for most of the diamonds. We had to give up using colour for clarity because we are now using colour for the number of observations in each pair of bins for price and carat (the “height” of each “bar”). We’ll return to this data when we talk about facets in a future lesson to see how we can add in one more categorical variable.
We can do a little better with a contour plot instead of colours. You can even add color=cut back in if you like. Try geom_density_2d_filled for an interesting variant.
diamonds |>
ggplot(aes(x = price, y = carat)) +
geom_density_2d() + scale_x_log10()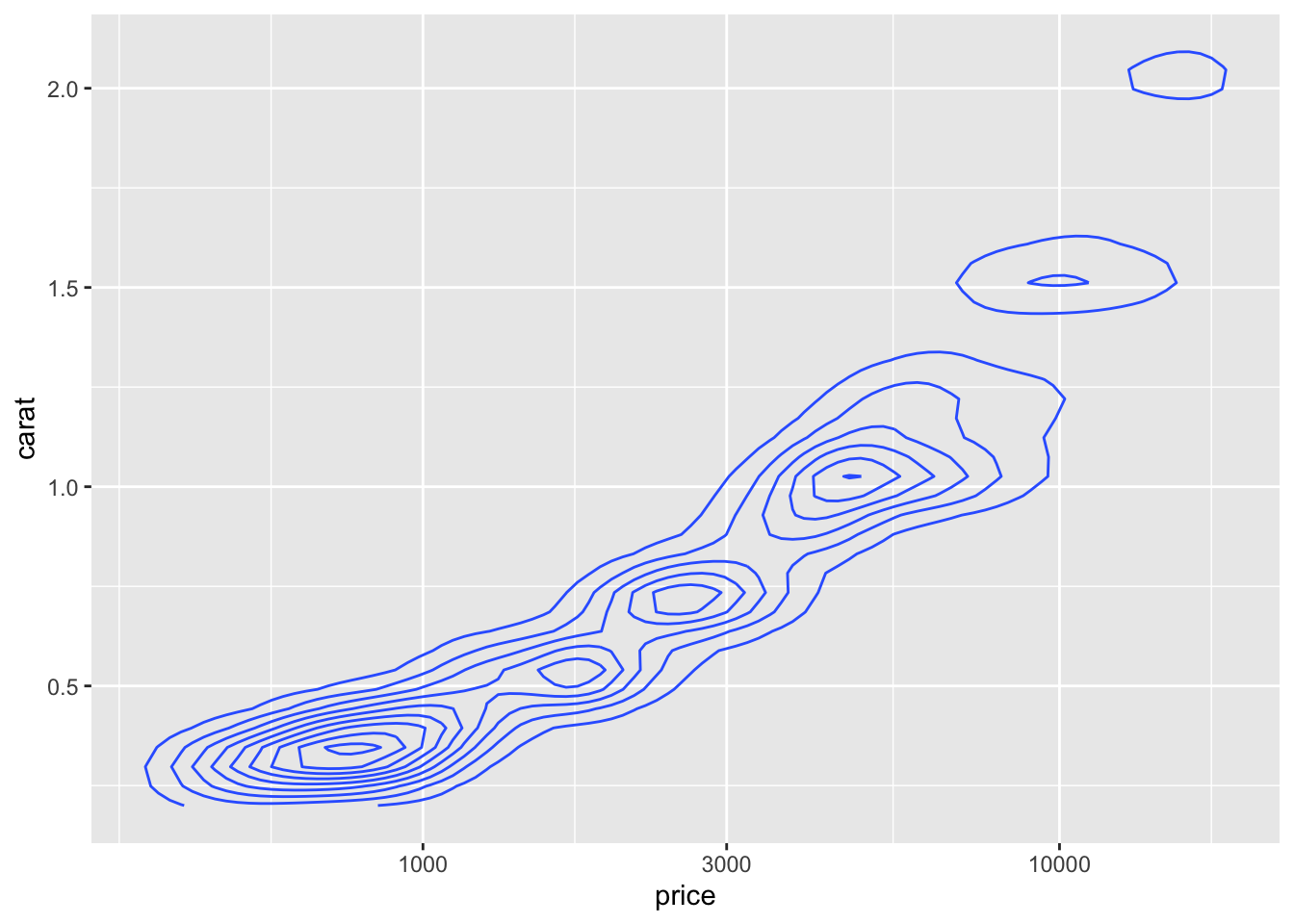
8.8.1 Statistics
We said that in addition to connecting variables to aesthetic features, we could use statistical transformations to create new derived variables for our plots. So let’s try that!
Instead of plotting a point for each diamond in the dataset, let’s compute averages and standard errors for all the diamonds group by clarity.
diamonds |>
ggplot(aes(x = price, y = clarity)) +
stat_summary(fun.data = "mean_se") + scale_x_log10()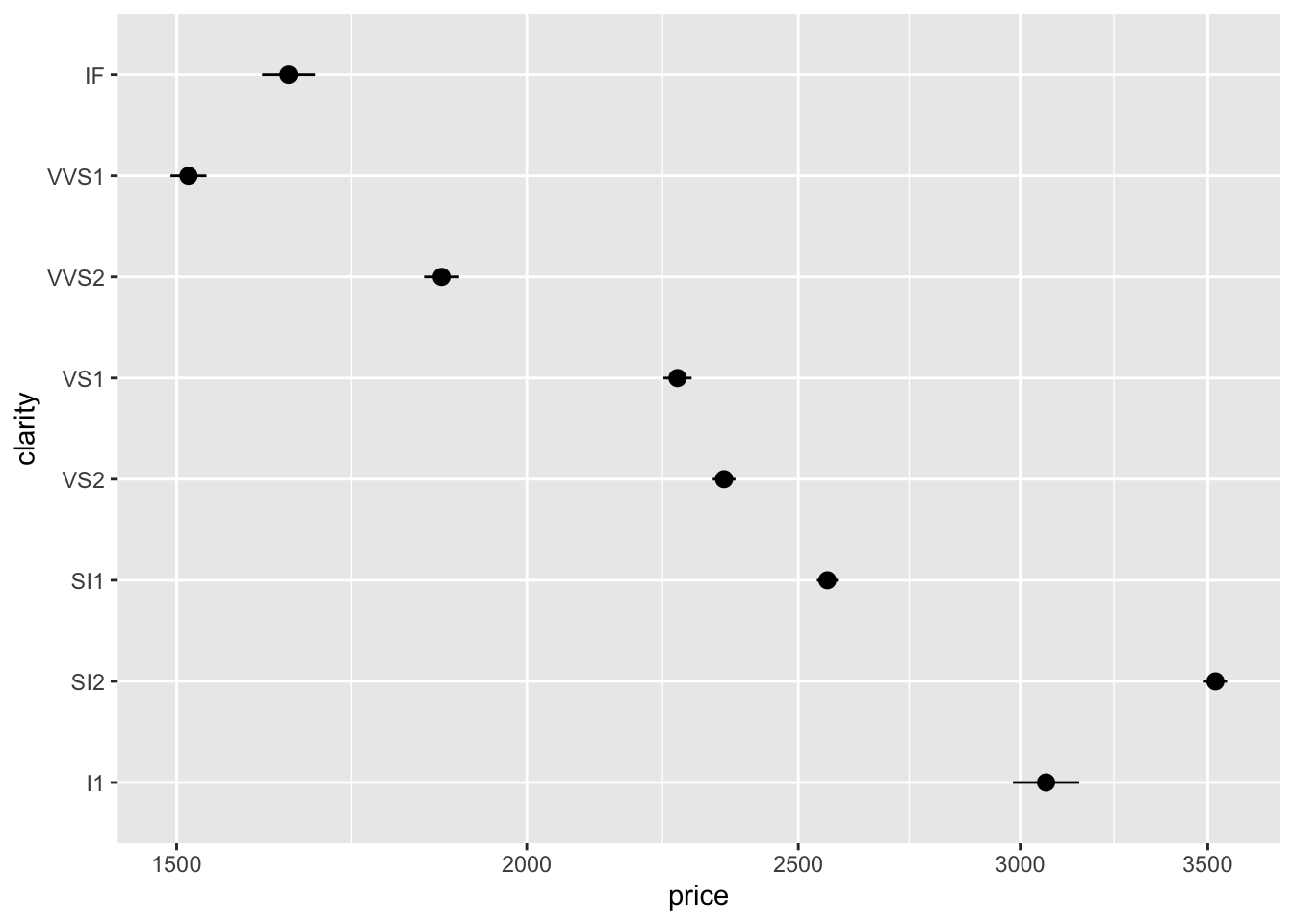
Now adding a colour for each cut doesn’t make the plot too complicated.
diamonds |>
ggplot(aes(x = price, y = clarity, color=cut)) +
stat_summary(fun.data = "mean_se") + scale_x_log10()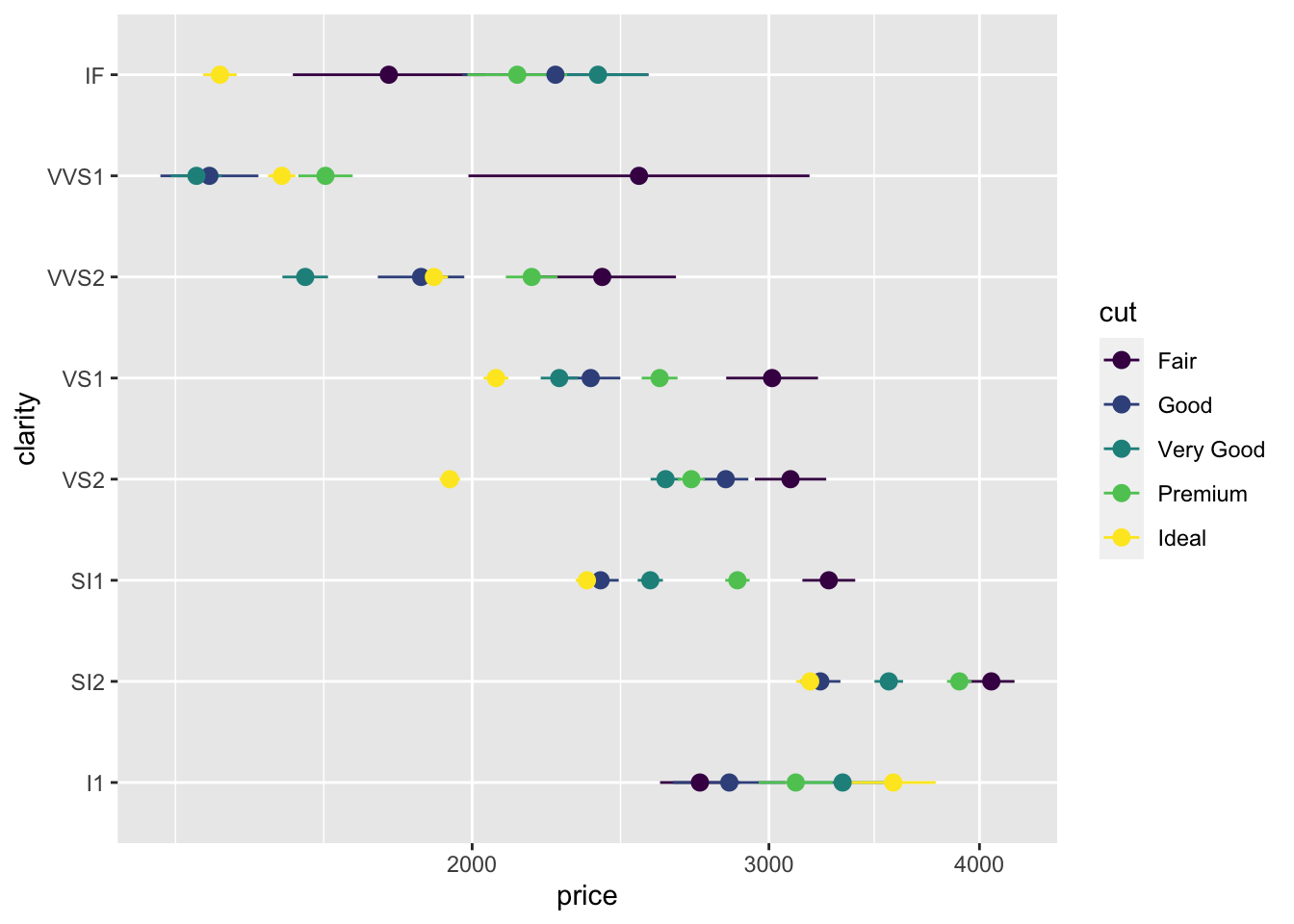
Most of the stat_ functions are directly linked to geom_ functions and you don’t need to know them, but a few like stat_summary or stat_unique are handy on their own. (Read the help page for stat_unique to learn what it does.)
8.9 Scales
We’ve seen how scales can be used to transform the x axis to a log scale, but there is a lot more we can do.
First, we can set the limits of the axis anywhere we want, to highlight some values or expand the range. (Maybe we have a very specific price range in mind for our data analysis.)
diamonds |>
ggplot(aes(x = price, y = clarity, color=cut)) +
stat_summary(fun.data = "mean_se") +
xlim(2000,4000)Warning: Removed 43582 rows containing non-finite outside the scale range
(`stat_summary()`).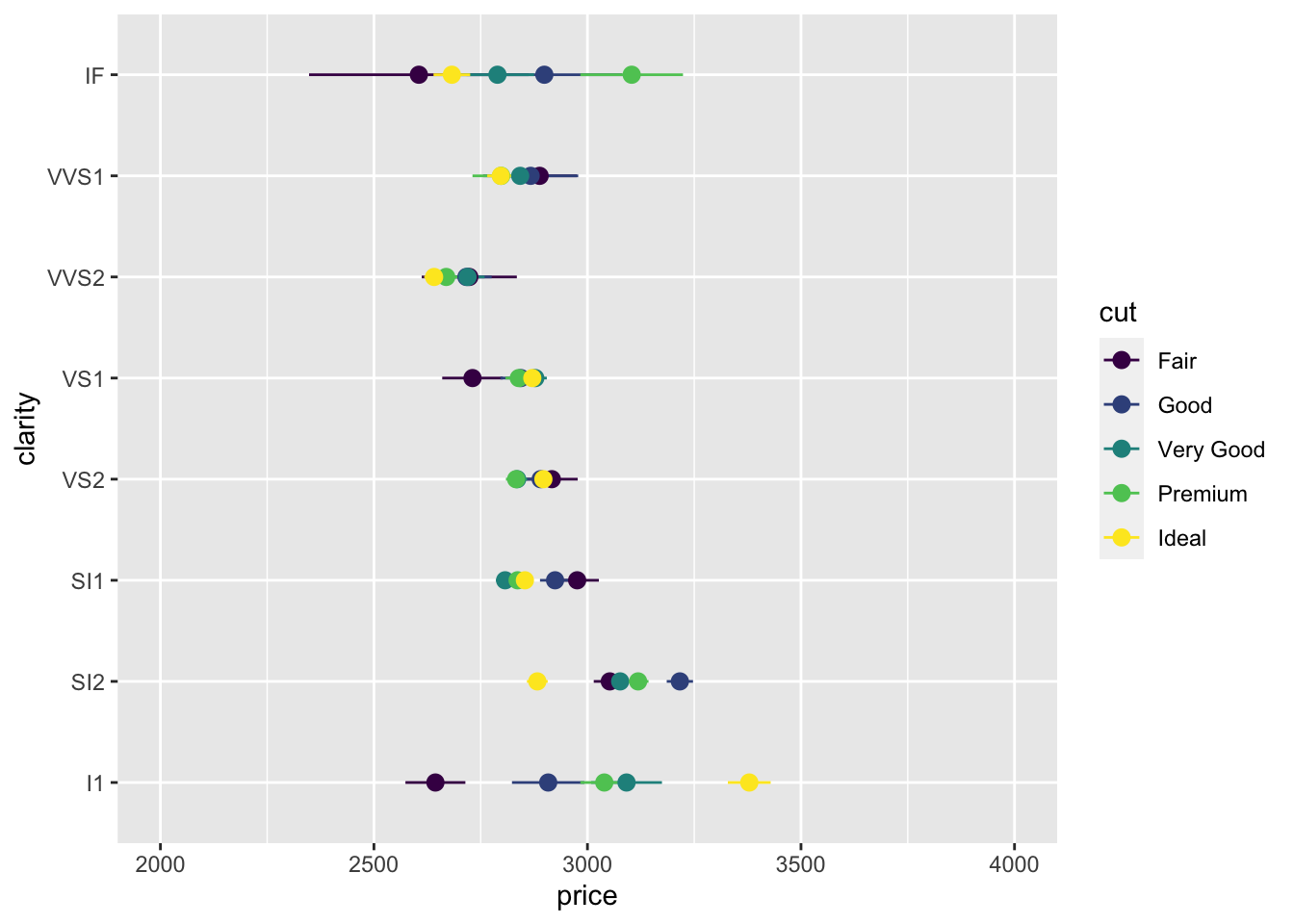
Compare a point on the previous two plots, for example the mean price of the Ideal IF diamonds. We can see the values are different, which is probably unexpected. The power of ggplot and accidentally shooting your own (data) foot off. The data outside this x range were discarded before the mean and standard error were computed. We got a warning, but it was hard to understand! So this is dangerous with summary statistics. Producing two plots (one with the restricted range and one with the full range and comparing them) like we just did here, will alert you to this error. We will learn to summarize data on our own in a future lesson to avoid this problem.
It’s perfectly safe to restrict the axes with raw unsummarized data. We still get a warning, but all the dots shown are untransformed, so we don’t need to wonder if the axis limits were set before or after transforming the data.
diamonds |> ggplot(aes(x = price, y = carat, color=cut)) +
geom_point(size=0.1) + scale_x_log10() +
xlim(2000,4000) + ylim(0,1.7)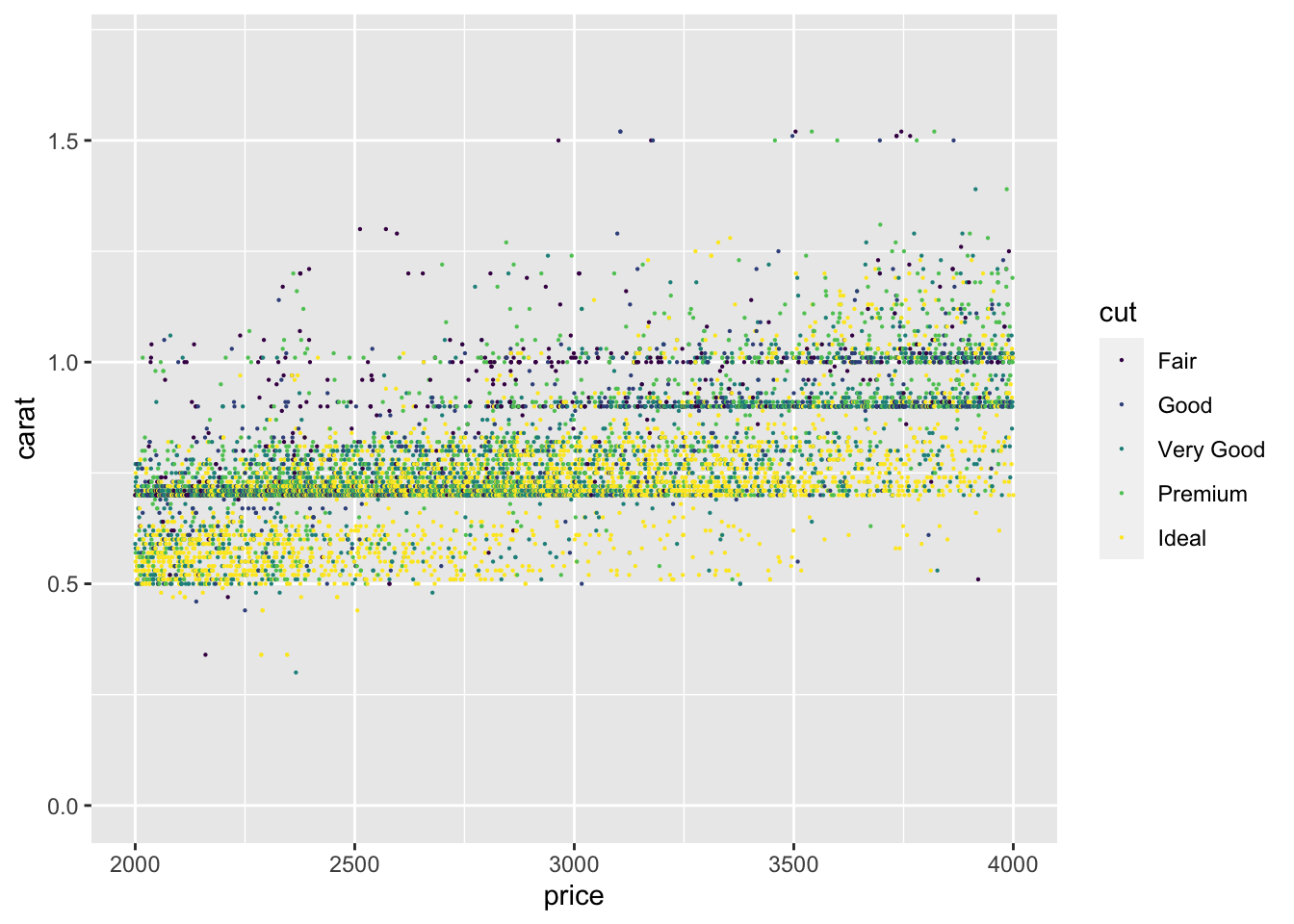
Colors are also controlled with a scale. We’ll have a whole lesson on colour, so here is just one example.
The yellow we used before won’t look good printed in a report, so let’s change the range of the colours.
diamonds |> ggplot(aes(x=price, fill=cut)) + scale_x_log10() +
geom_histogram(bins = 10, position="dodge") +
scale_fill_viridis_d(begin = 0.0, end = 0.8)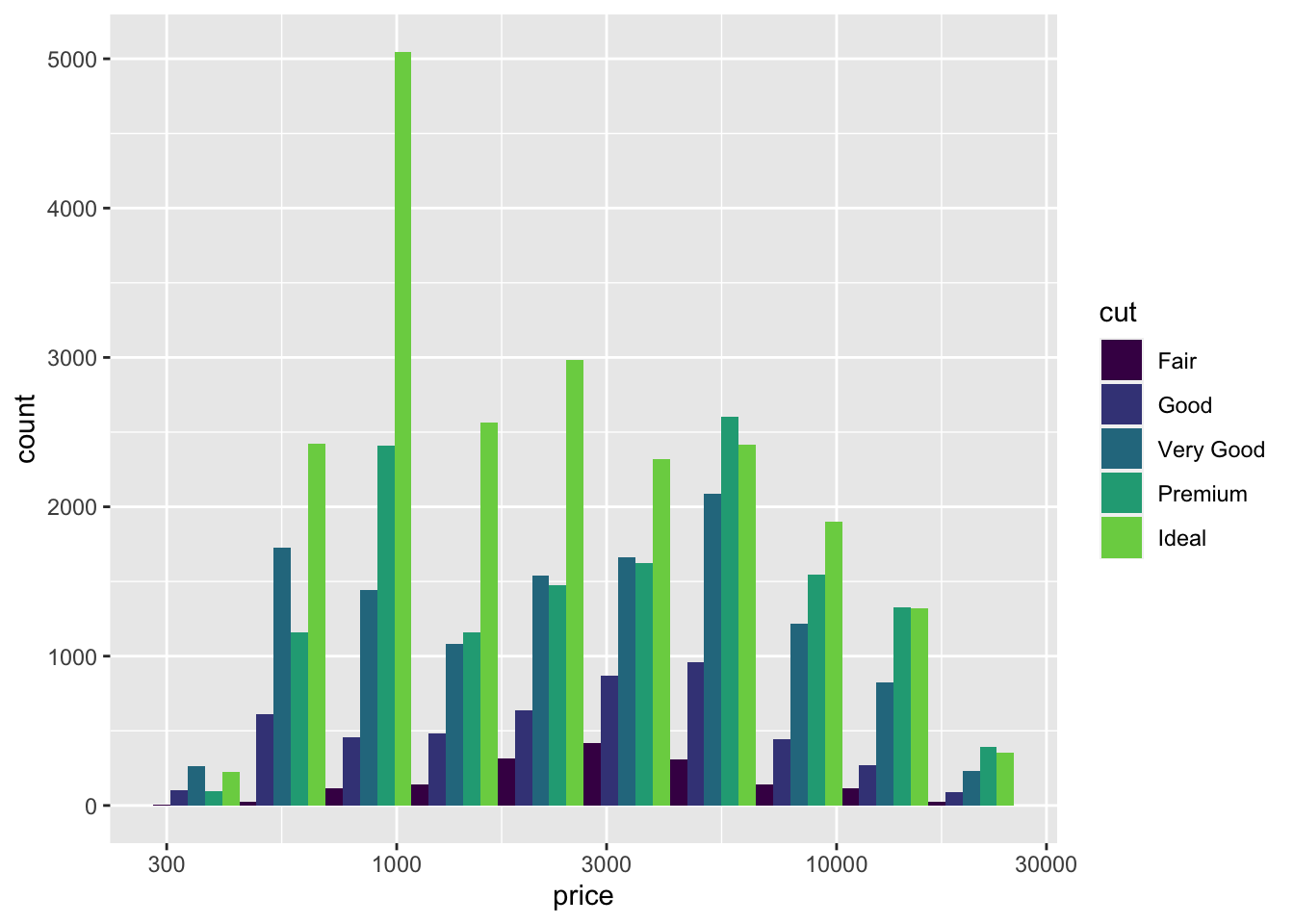
The viridis colour scale is supposed to be colour-blind friendly and to translate well when printed in gray scale on paper. It’s a range of colours selected between two extremes. Experiment with different values for begin and end between 0 and 1.
8.10 Annotations
The most important annotations are labels for the axes, guides for colours and shapes, and the title, subtitle, and caption. Here’s an example showing how to change each one using the labs (for labels) function.
diamonds |>
ggplot(aes(x=price, fill=cut)) + scale_x_log10() +
geom_histogram(bins = 10, position="dodge") +
scale_fill_viridis_d(begin = 0.0, end = 0.8) +
labs(x = "Price ($, log scale)",
y = "Number of diamonds",
fill = "Cut",
title = "Diamond price varies with cut quality",
subtitle = "I don't often use subtitles, but you can",
caption = "Used to show the source of the data or other note")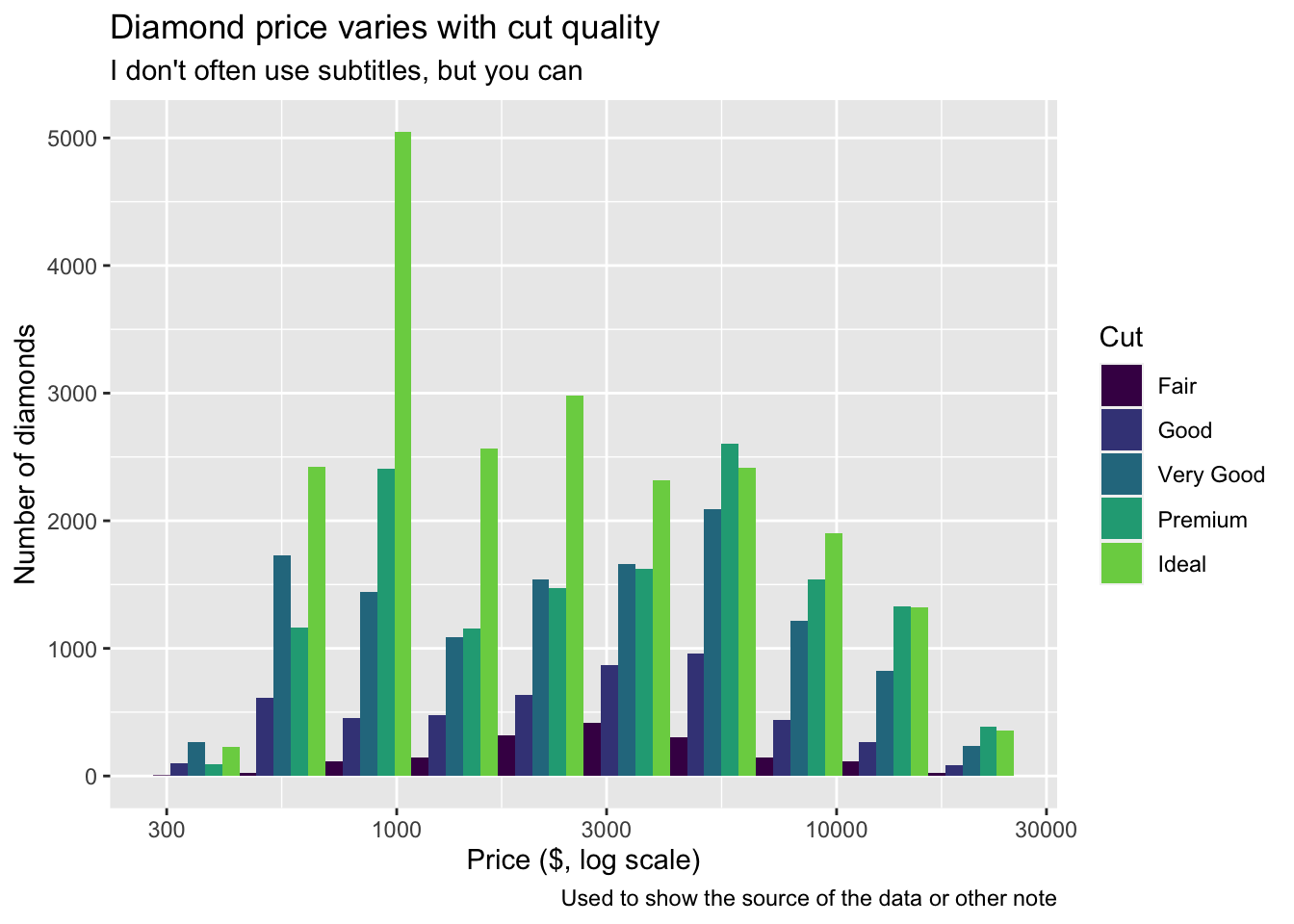
Another kind of annotation adds text to a figure. It’s called an annotation instead of a geom because the annotation is a custom thing you add that doesn’t come from the data. Sometimes this is a corporate branding graphic. Or a cartoon reminding the reader what the data are about. Here I’ll add a text message.
diamonds |>
ggplot(aes(x=price, fill=cut)) + scale_x_log10() +
geom_histogram(bins = 10, position="dodge") +
annotate(geom="text", x = 1300, y = 4500,
label = "Compare the peaks for\nIdeal and Good.",
hjust = 0, vjust = 0.5, size = 5)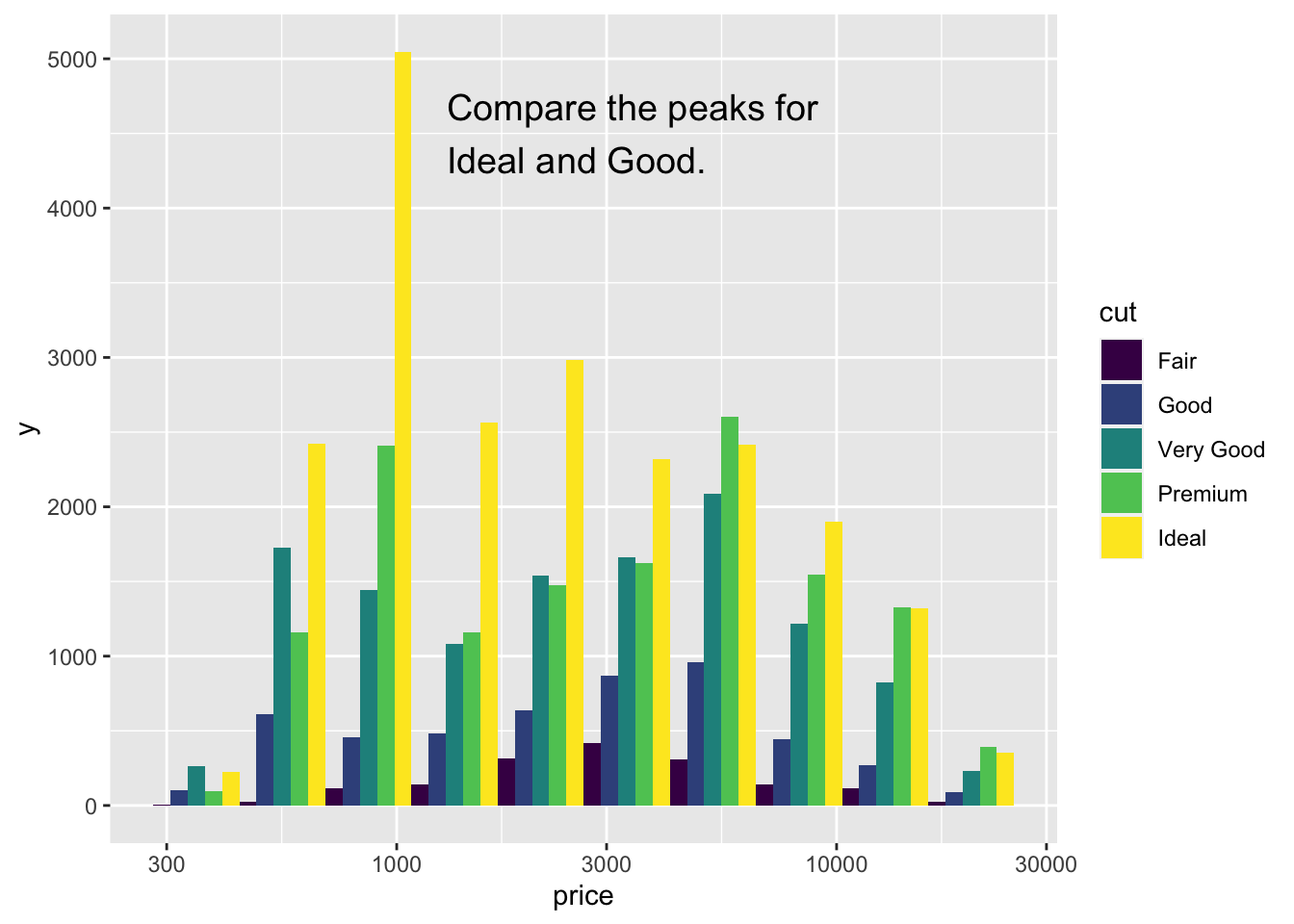
You can add annotations in the shape of points or arrows too.
A better way to annotate is to create a data frame with x and y locations and a label. Here I’ll find the average price and carat for each combination of cut and clarity, use colour for cut and add a text label for clarity. We’ll learn more about summarizing data later, so feel free to skip over the calculation and focus on the plotting for now.
s <- diamonds |> group_by(cut, clarity) |>
summarize(price = mean(price), carat = mean(carat),
.groups = "drop")
s |>
ggplot(aes(x= price, y = carat, color = cut)) +
scale_x_log10() +
geom_point() +
geom_text(aes(label = clarity ))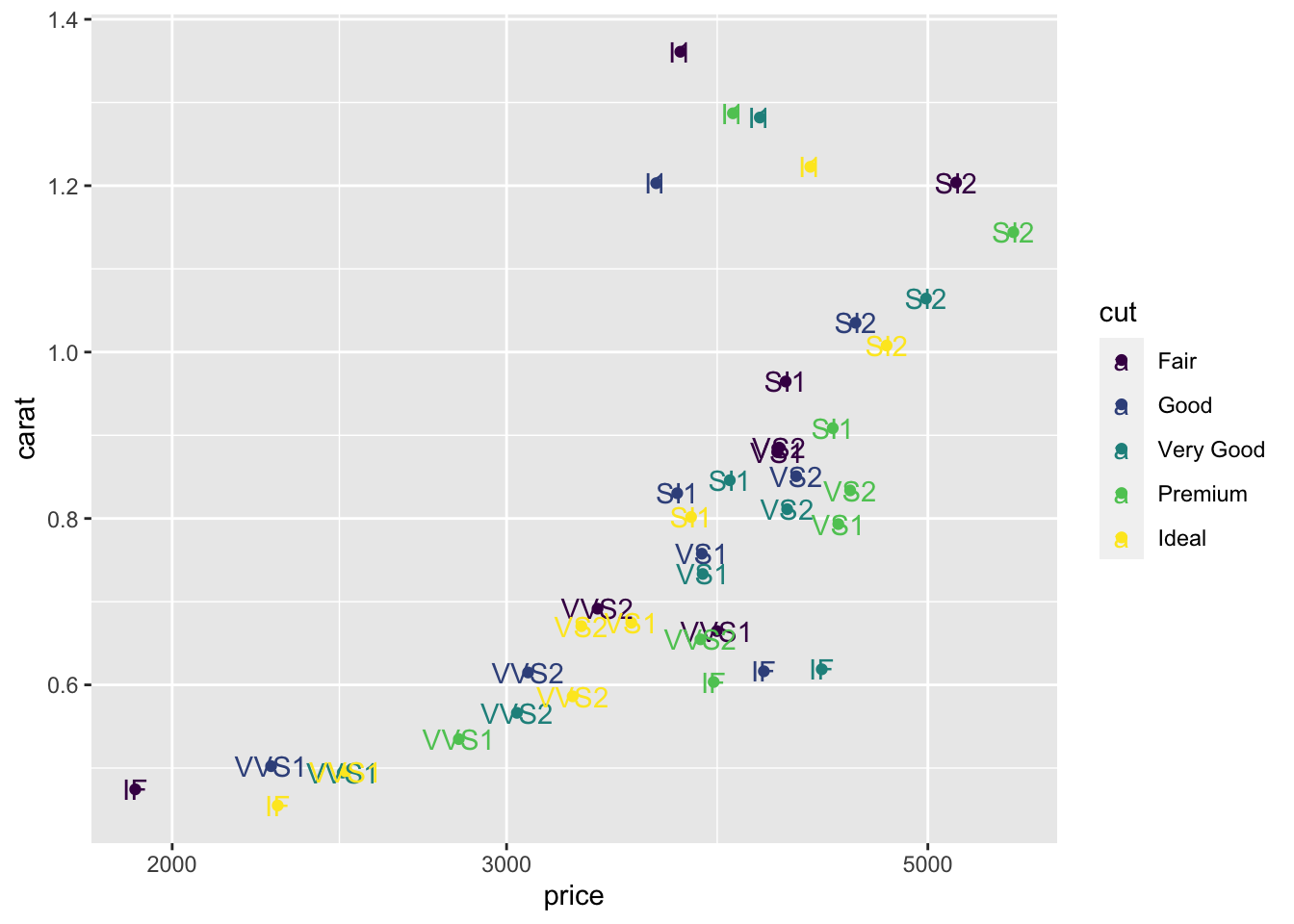
There’s a few problems with that graph! The labels are coloured too. The color scale for “cut” looks strange. The text labels are on top of the points.
The colour of the labels comes from the inheritance of the aesthetics. That’s easy to fix. Only map clarity to a colour in the geom_point.
s |>
ggplot(aes(x= price, y = carat)) + scale_x_log10() +
geom_point(aes(color=cut)) +
geom_text(aes(label = clarity ))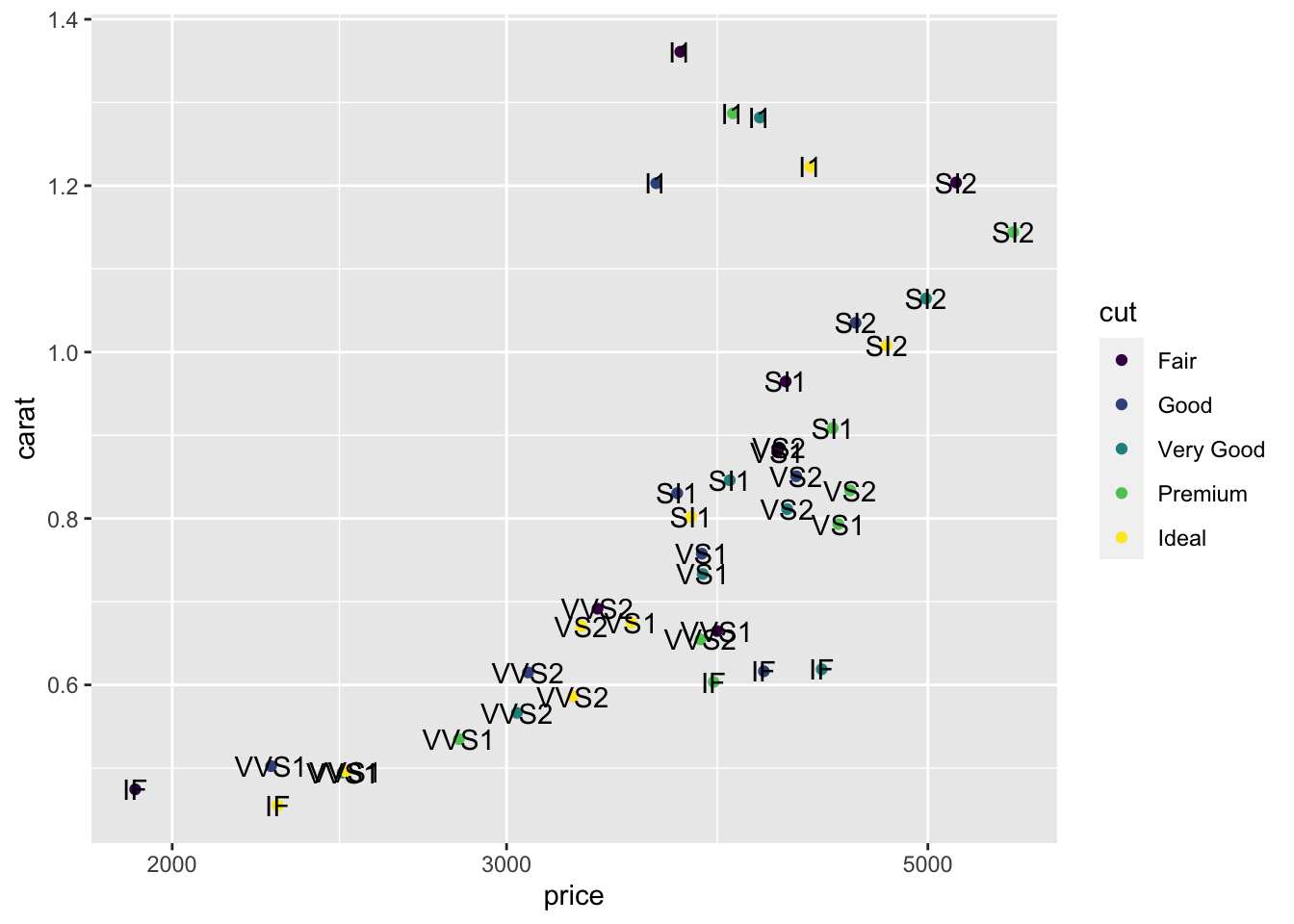
A simple change makes a huge difference.
We can use geom_text_repel from the ggrepel package to fix the placement of the labels. I’ll shrink the size of the text a bit too.
library(ggrepel)
s |>
ggplot(aes(x= price, y = carat)) + scale_x_log10() +
geom_point(aes(color=cut)) +
geom_text_repel(aes(label = clarity), size = 3)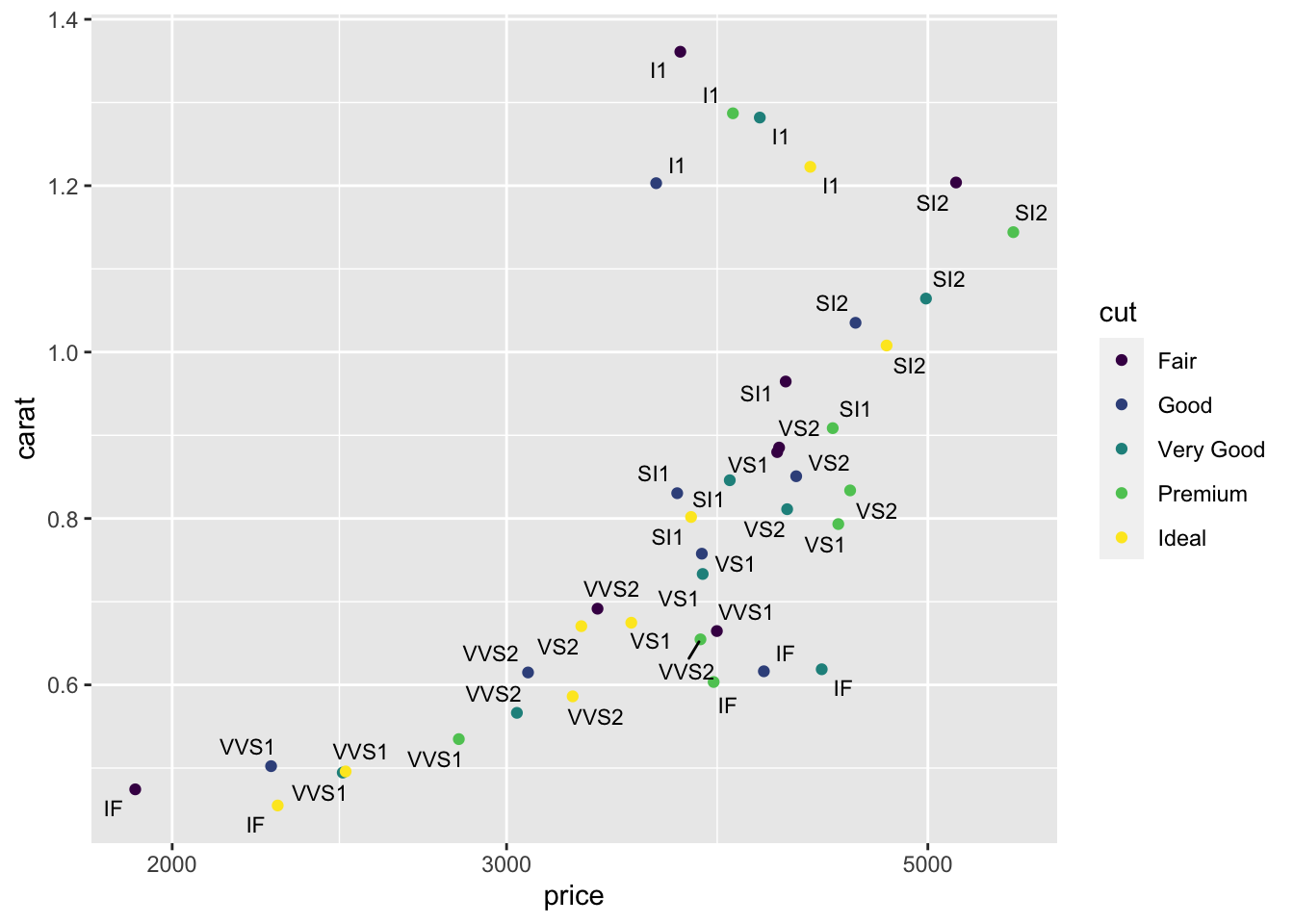
There are too many labels on the plot so it’s not a good final visualization, but it demonstrates how to add labels and make a plot that might be very useful for you as you explore a dataset.
8.11 Theme
The theme allows you to set text font and size for labels and numbers on scale, line thicknesses for axes and ticks, position of the guides and many other features. You can also use predefined themes created by others. Here are a few examples that I find useful as an introduction to this topic.
My favourite gets rid of the gray background.
s |> ggplot(aes(x= price, y = carat, color = cut)) + scale_x_log10() +
geom_point() +
theme_bw()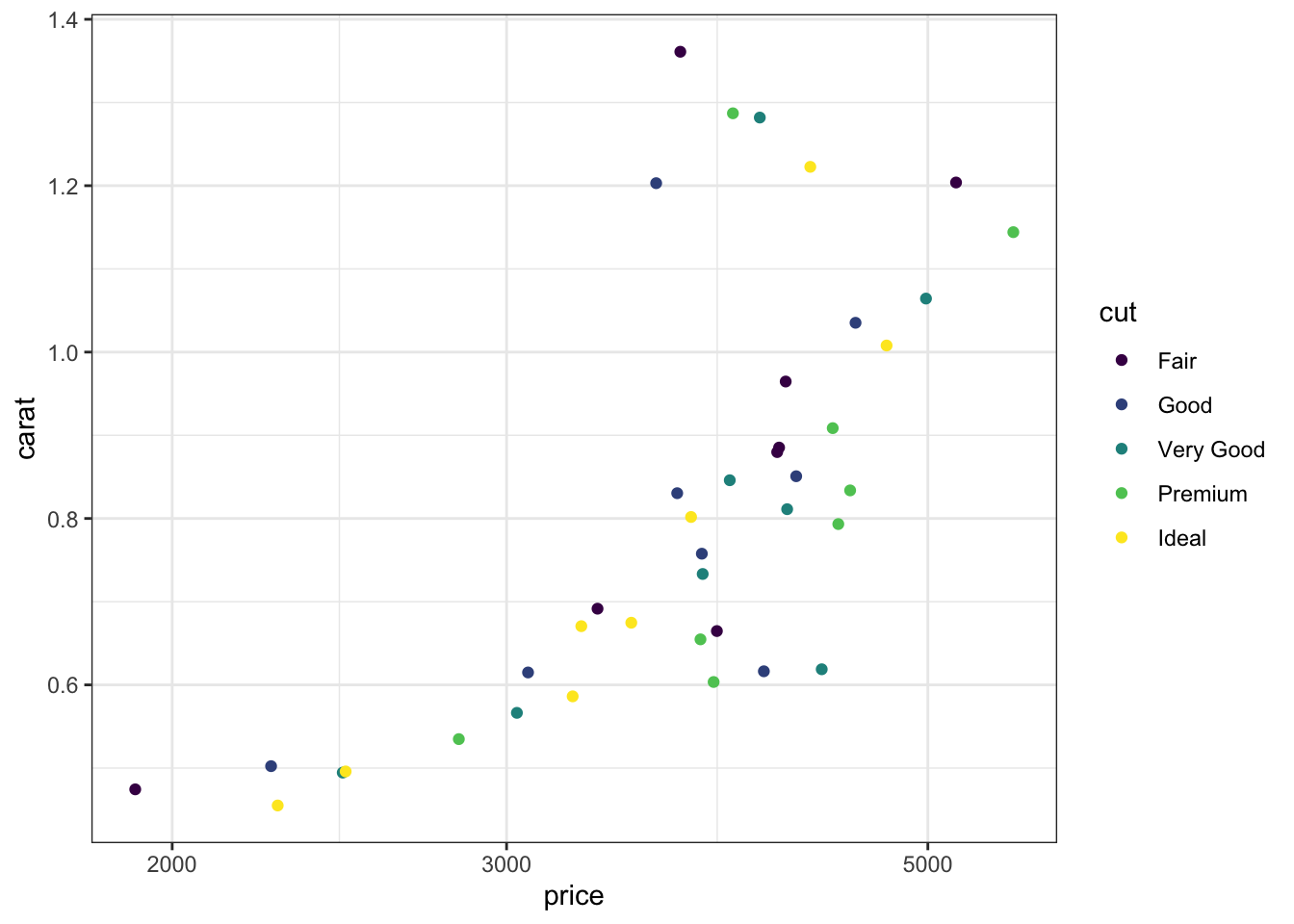
My second favourite change is to make the text larger for all elements.
s |> ggplot(aes(x= price, y = carat, color = cut)) + scale_x_log10() +
geom_point() + theme_bw() +
theme(text = element_text(size=20))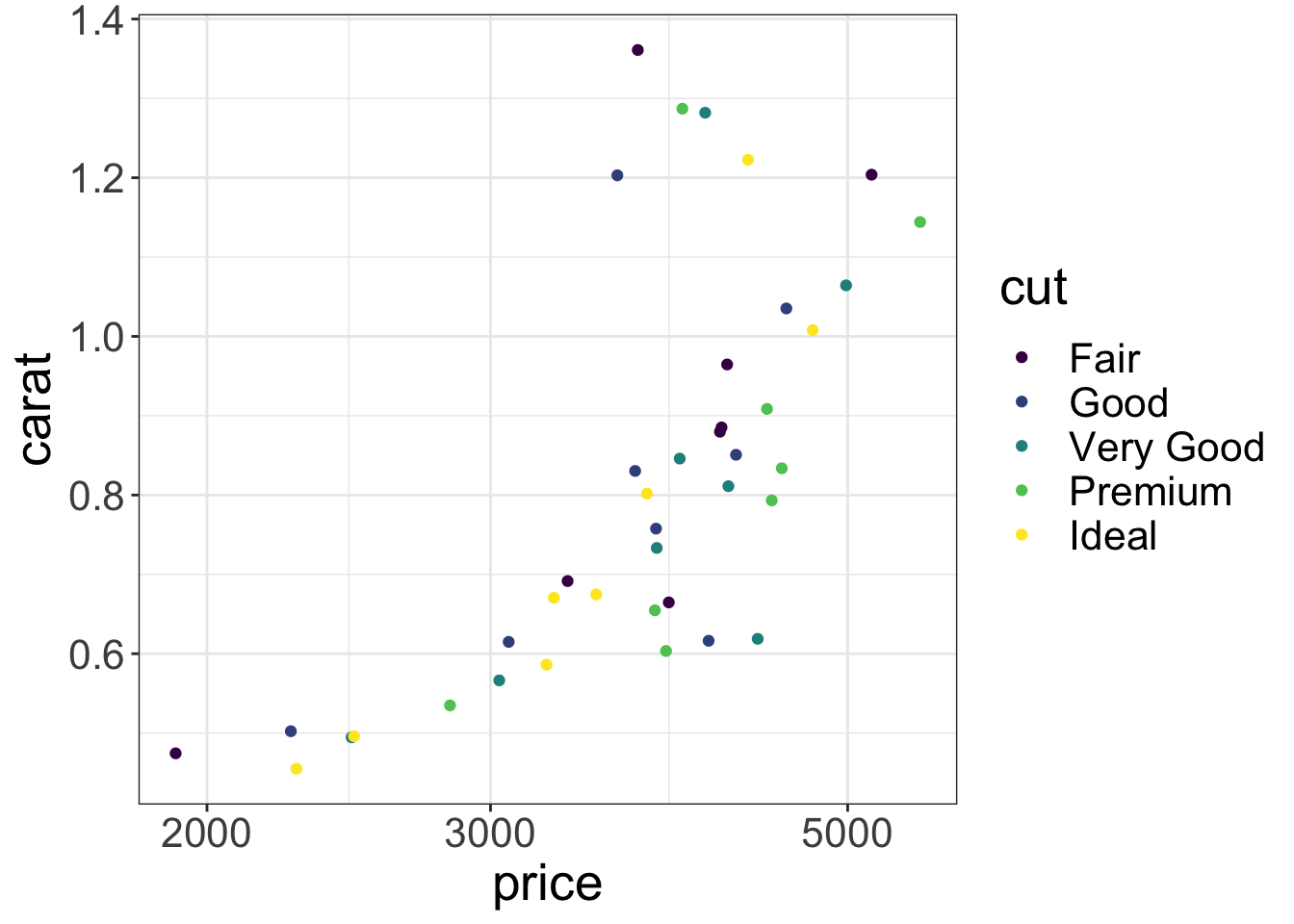
If you have room you can put the guide inside the plot. The coordinates range from 0 to 1 on both scales from left to right and bottom to top.
s |> ggplot(aes(x= price, y = carat, color = cut)) + scale_x_log10() +
geom_point() + theme_bw() +
theme(text = element_text(size=20),
legend.position = c(0.15,0.75))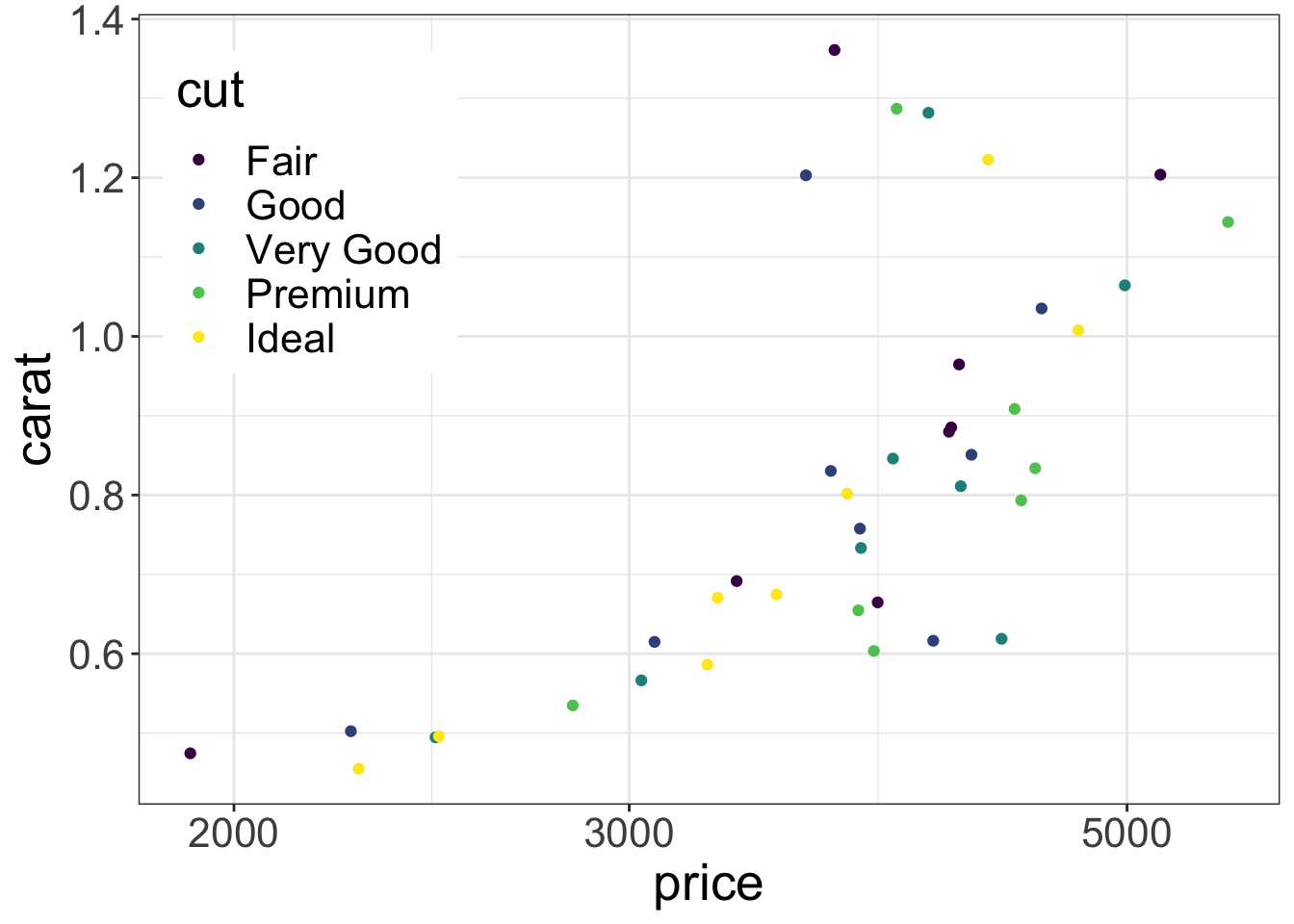
8.12 Further reading
- Healy Chapter 3 on making plots
- A chapter on these ggplot concepts from a data science course
- A ggplot cheatsheet summarizing a huge amount of information in two pages
- A guide to themes from the ggplot2 book
- A whole book on ggplot2