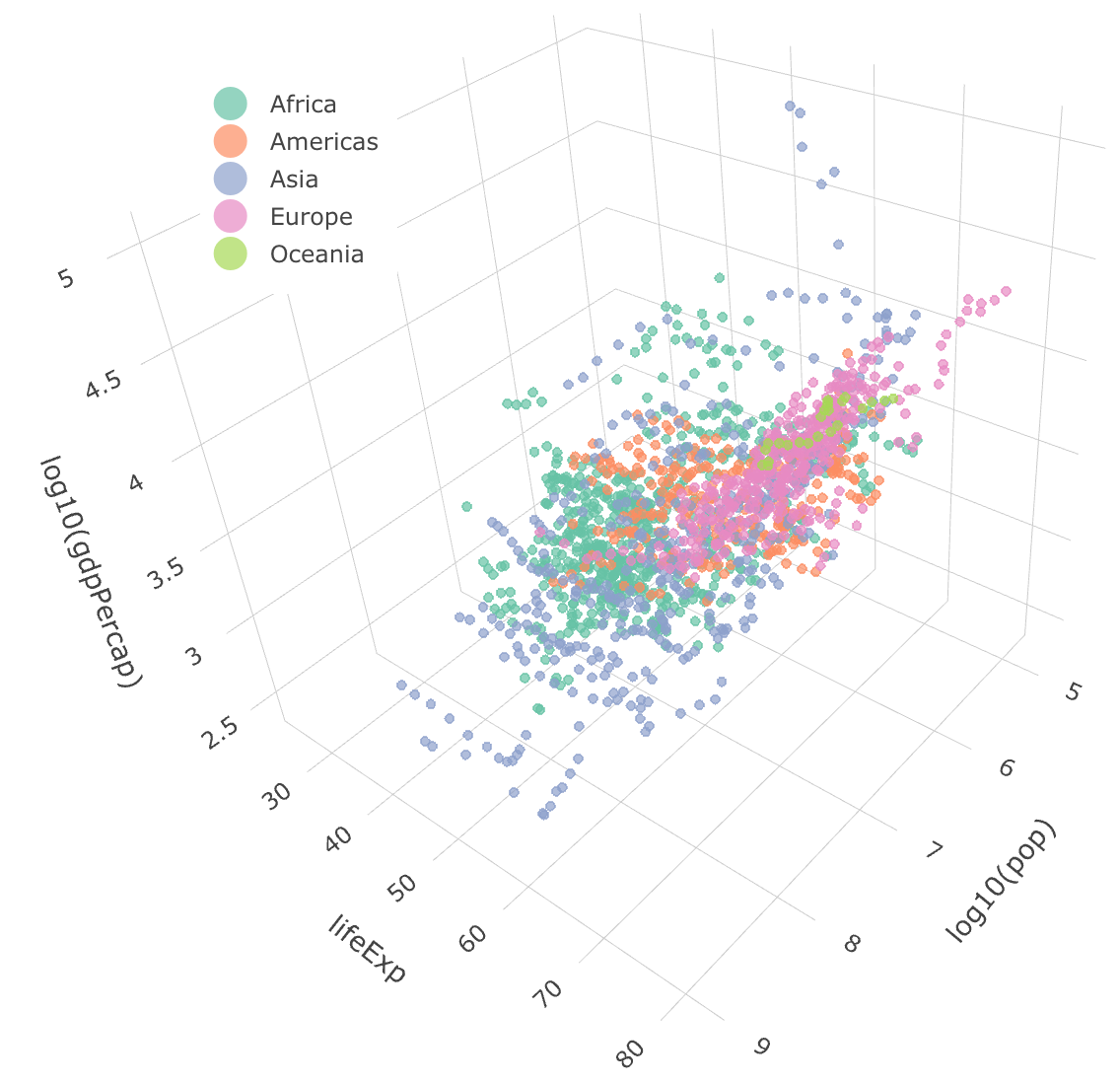
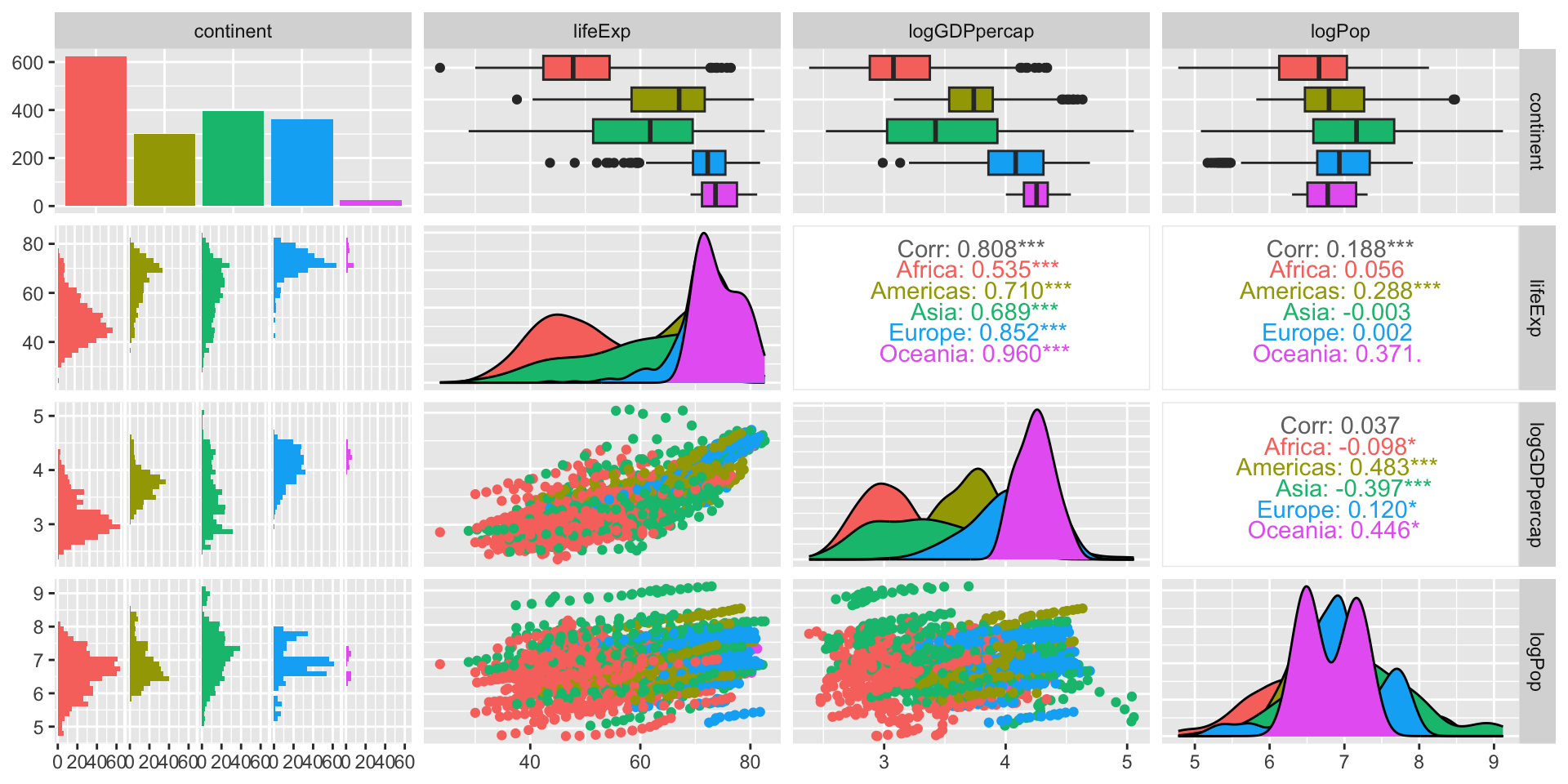
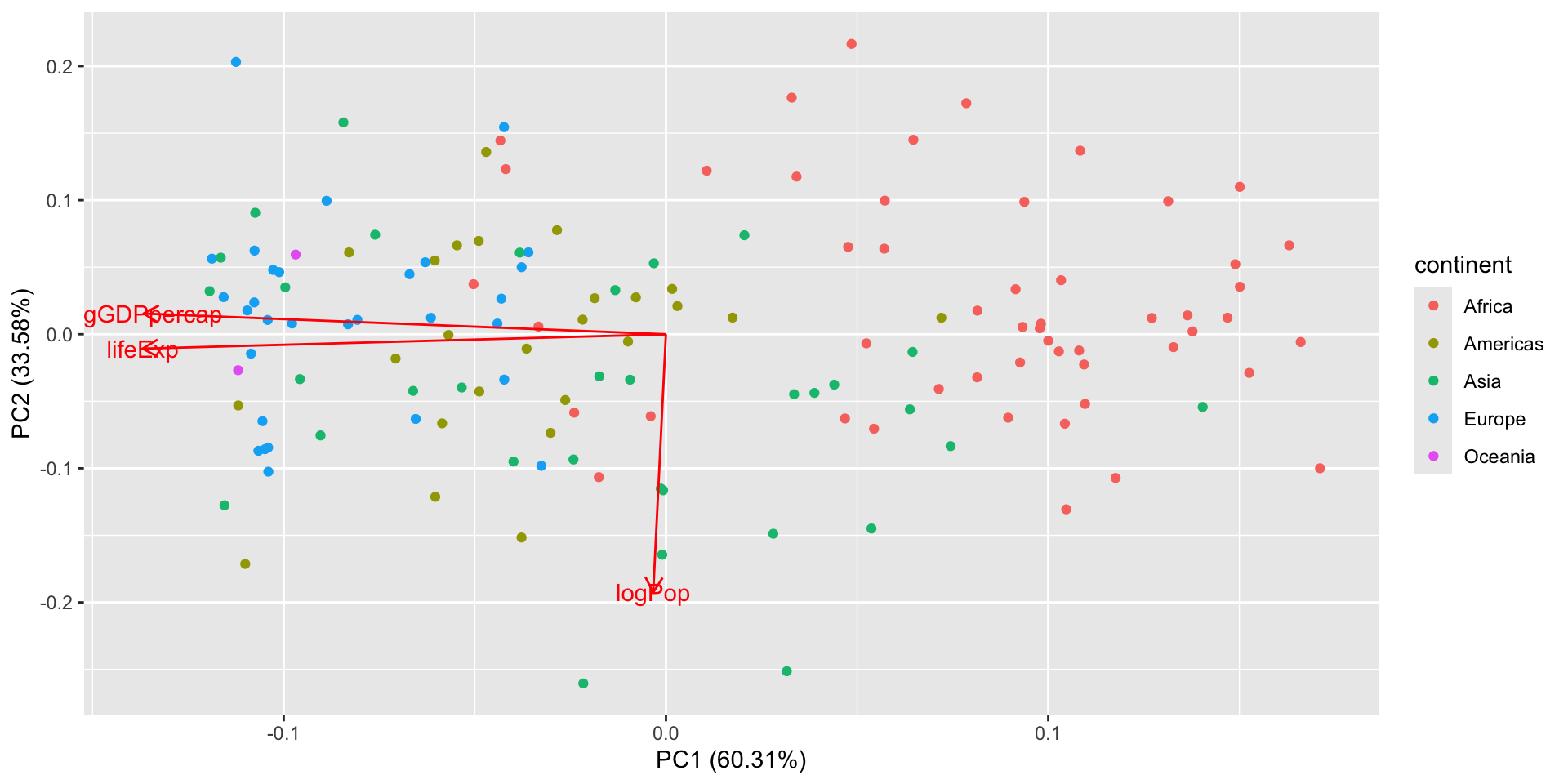
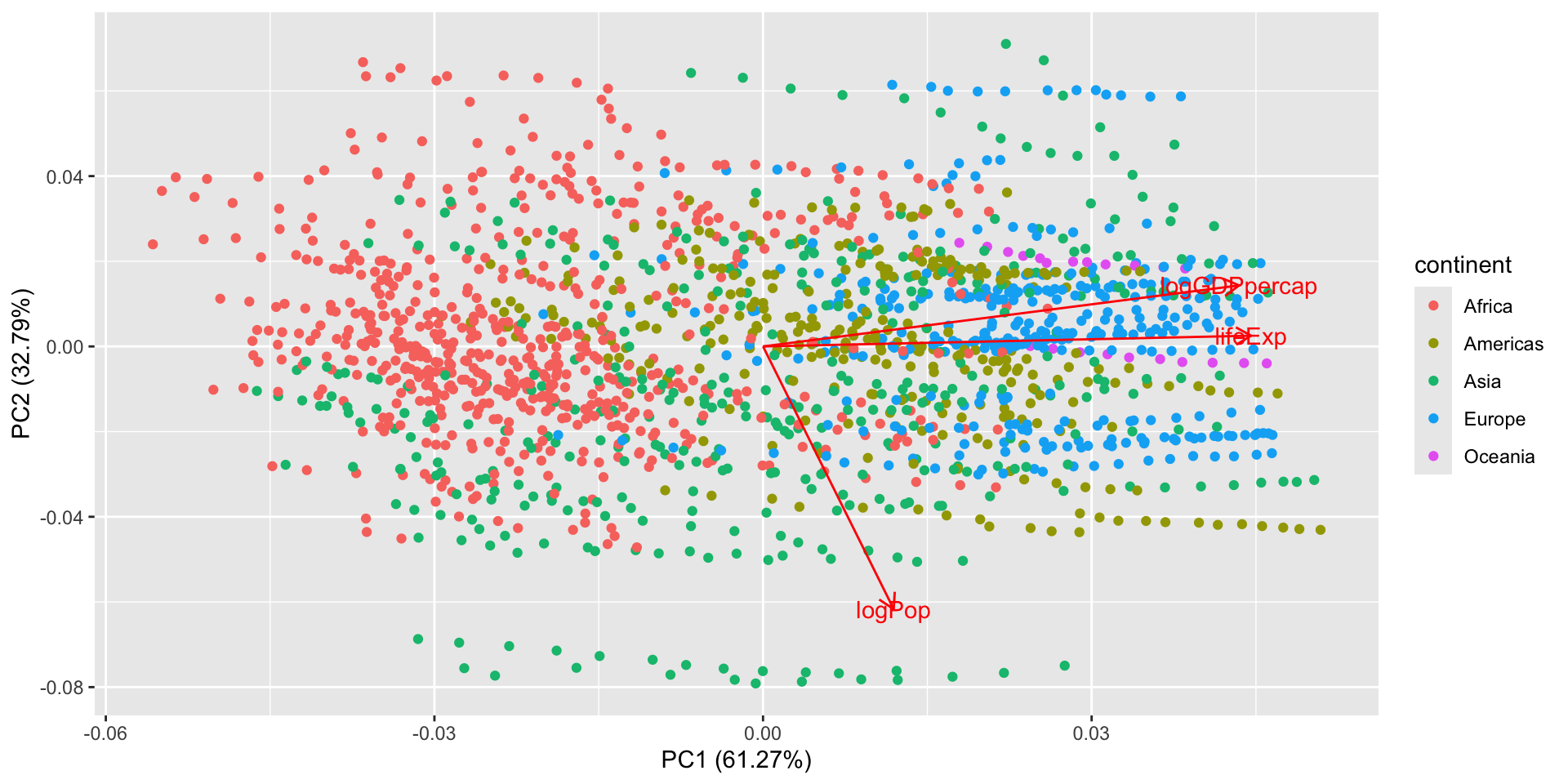
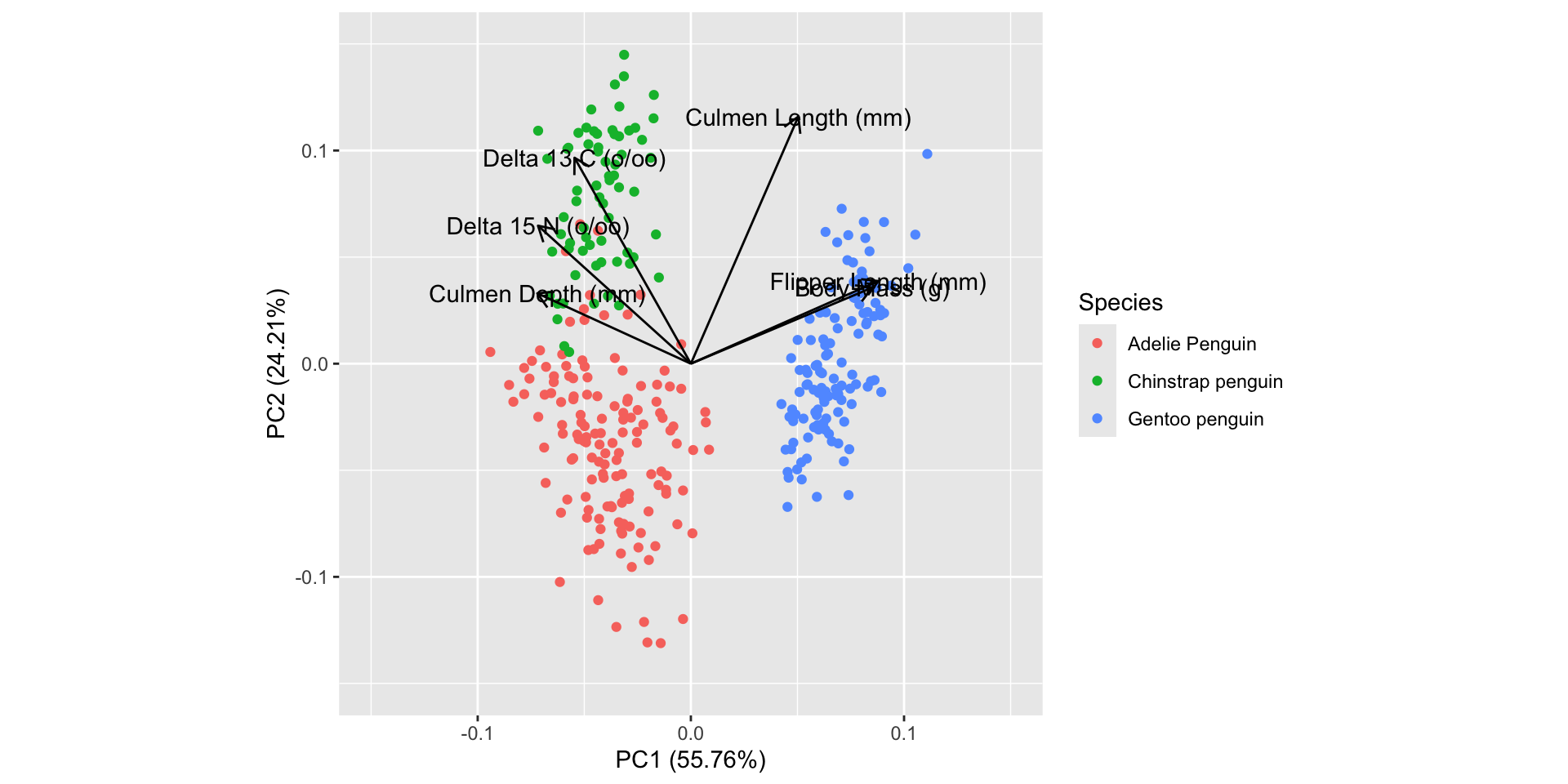
my_penguins_raw = penguins_raw |> select(-`Sample Number`) |>
select(Species, where(is.numeric) ) |> na.omit() |>
mutate(Species = str_remove(Species, "\\(.*\\)"))
pca2 <- my_penguins_raw |> select(-Species) |> prcomp(scale=TRUE)
autoplot(pca2, data = my_penguins_raw,
loadings=TRUE, loadings.label = TRUE,
loadings.label.colour = "black", loadings.colour = "black",
colour = 'Species') + xlim(-0.15, 0.15) + ylim(-0.15, 0.15)